SQL Server Express 2012 Database Size Limit. Sql server express 2018 ограничения
Как хранить более 10 ГБ в SQL Express
Давайте сначала вспомним что бесплатная Express версия имеет следующие ограничения:
Может использовать только 1 Физический процессор (но все ядра)
- Использует только 1 ГБ оперативной памяти (на компьютере может быть установлен любой объем)
Имеет ограничение 10ГБ на файлы данных (начиная с версии SQL Server 2008 R2)
Ограничение касается только фалов данных, но не файлов логов;
- Ограничение распространаяется только на одну базу данных, т.е. вы можете иметь несколько баз на одном инстансе SQL Express;
Ограничение не распространяется на FileStream.
К примеру у нас в базе имеется таблица dbo.Data следующей структуры, и она занимает в БД более 80% места.
use master; go create database BigDb; go use BigDb; go create table dbo.Data ( Id int , CreatedDate datetime2(0) not null , PlaceHolder char(100) not null , constraint PK_Data primary key clustered (Id) ) -- заполним базу данных данными, чтобы было с чем работать ; with cte ( id ) as ( select 1 union all select id + 1 from cte where id < 500000 ) insert into BigDb.dbo.Data ( Id , CreatedDate , PlaceHolder ) select id , dateadd(minute, id, '20120826') , 'cte data' from cte option ( maxrecursion 0 ) Давайте распределим эту таблицу к примеру на 4 базы. Вообще выбор на сколько частей можно разделить таблицу зависит от баланса между сложностью поддержки мнжества баз, и получаемым в результате объемом хранения. Т.е. не стоит создавать 100 баз данных, потому что их будет сложно поддерживать, да SQL Server будет тормозить (не забывайте про другие ограничения).В нашем примере у нас такого столбца нет, поэтому нам придется добавить суррогатный тип записи. Итак приступим. Создаем 4 дополнительные базы данных и в них таблицы аналогичной структуры.
use master; go create database BigDb1; go create database BigDb2; go create database BigDb3; go create database BigDb4; go use BigDb1; go create table dbo.Data ( Id int , CreatedDate datetime2(0) not null , DB tinyint not null , PlaceHolder char(100) not null , constraint PK_Data primary key clustered (id, DB) , constraint CH_CreatedDate check ( DB = 1 ) ) go use BigDb2; go create table dbo.Data ( Id int , CreatedDate datetime2(0) not null , DB tinyint not null , PlaceHolder char(100) not null , constraint PK_Data primary key clustered (id, DB) , constraint CH_CreatedDate check ( DB = 2 ) ) go use BigDb3; go create table dbo.Data ( Id int , CreatedDate datetime2(0) not null , DB tinyint not null , PlaceHolder char(100) not null , constraint PK_Data primary key clustered (id, DB) , constraint CH_CreatedDate check ( DB = 3 ) ) go use BigDb4; go create table dbo.Data ( Id int , CreatedDate datetime2(0) not null , DB tinyint not null , PlaceHolder char(100) not null , constraint PK_Data primary key clustered (id, DB) , constraint CH_CreatedDate check ( DB = 4 ) ) go Обратите внимание на несколько важных вещей. Все они нужны для того чтобы мы смогли создать секционированное представление.Мы добавили столбец DB tinyint not null - это будет наш сурогатный тип записи (разделитель)
Мы добавили в структуру таблицы ограничение, чтобы в каждой из таблиц мог храниться только определенный тип записи CH_CreatedDate check ( DB = 4 ) например.
- Мы включили столбец DB в главный ключ таблицы PK_Data primary key clustered (id, DB)
Теперь, можно проверить как данные распределились по базам
select * from BigDb1.dbo.Data select * from BigDb2.dbo.Data select * from BigDb3.dbo.Data select * from BigDb4.dbo.Data Теперь старую таблицу нужно удалить, и работаеть с данными через представление dbo.vData, для простоты можете дать представлению тоже название что имела таблица т.е. dbo.Data.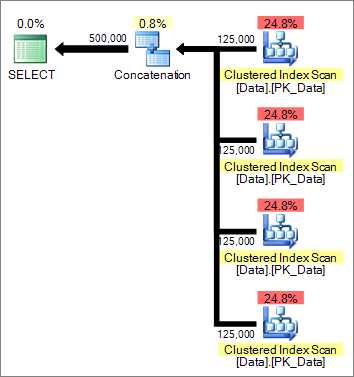 |
| Как видите были просканированы 4 таблицы которые находятся в разных базах, после чего результаты были объеденены |
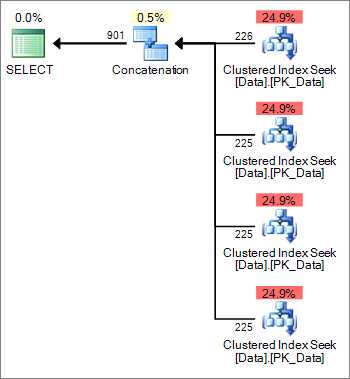 |
| Тожесамое произошло и здесь, только в место сканирования мы имеем поиск в кластерном индексе |
| Тут произведен поиск в кластерных индексах только двух таблиц |
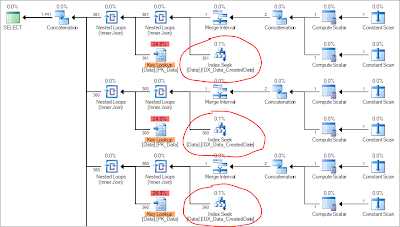 |
| Некластерные индексы используютя в плане |
Применив такой подход вы конечно же столкнетесь с дополнительными усилиями по сопровождению ваших данных. Ведь теперь у вас не одна база данных а несколько :). Но тем не менее возможно это поможет вам сэкономить пару лишних баксов.
qwertysql.blogspot.com
Ограничения SQL Server Express MS SQL Server
Мой хостинг-провайдер (Rackspace) предлагает полностью управляемый выделенный сервер с установленной версией SQL Server (). Моя компания занимается веб-разработкой и имеет около 20 клиентов, использующих ASP.Net + SQL Server 2005.
Я собираюсь сократить расходы, установив вместо этого бесплатный SQL Server 2008 Express. Я знаю о 1GB RAM и 4GB / database (это верно?). Я хотел бы знать:
Существует ряд ограничений, в частности:
- Ограничено одним процессором (в 2012 году это ограничение было изменено на «Менее одного сокета или четырех ядер», поэтому возможна многопоточность)
- 1 ГБ оперативной памяти (то же в 2008/2012)
- Размер базы данных 4 ГБ (увеличен до 10 ГБ в SQL 2008 R2 и SQL 2012) на базу данных
http://www.dotnetspider.com/tutorials/SqlServer-Tutorial-158.aspx http://www.microsoft.com/sqlserver/2008/en/us/editions.aspx
Что касается количества баз данных, в этой статье MSDN нет предела:
Предел размера базы данных 4 ГБ применяется только к файлам данных, а не к файлам журналов. Тем не менее, нет ограничений на количество баз данных, которые могут быть присоединены к серверу.
Однако, как упоминалось в комментариях и выше, ограничение размера базы данных было увеличено до 10 ГБ в 2008 R2 и 2012 году. Кроме того, этот предел в 10 ГБ применяется только к реляционным данным, а данные Filestream не учитываются до этого предела ( http: // msdn .microsoft.com / en-us / library / bb895334.aspx ).
Еще одно ограничение для рассмотрения заключается в том, что выпуски SQL Server Express переходят в режим ожидания после периода неиспользования.
Понимание поведения SQL Express: использование ресурса в режиме ожидания, AUTO_CLOSE и пользовательские экземпляры :
Когда SQL Express простаивает, он агрессивно обрезает рабочую память, записывая данные кэширования на диск и освобождая память.
Но это легко обойти: есть ли способ остановить SQL Express 2008 от Idling?
Вы можете создать пользовательские экземпляры и поговорить о каждом приложении с его собственным SQL Express.
Количество баз данных не ограничено.
Если вы переключитесь с Web на Express, вы больше не сможете использовать службу агента SQL Server, поэтому вам нужно настроить другой планировщик для обслуживания и резервного копирования.
Вы не можете установить Integration Services с ним. Экспресс не поддерживает службы интеграции. Поэтому, если вы хотите построить SSIS-пакеты, вам понадобится хотя бы стандартная версия.
Подробнее см. Здесь .
sqlserver.bilee.com
server-express - Ограничение размера базы данных SQL Server Express 2012
SQL Server Express only imposes file size limits on data files, log files can grow to any size. The Size shown on the database properties window is the data and log file combined sizes.
Somewhat confusingly though, the Free Space value shown on this window only relates to the data file(s). If you'd like to see this in more detail, I'd recommend querying the system tables rather than relying on the SSMS GUI (which isn't always going to give you the information you want/need). The following script will show some more detailed information about data file sizes/growth settings:
SELECT [TYPE] = DF.TYPE_DESC ,[FILE_Name] = DF.name --,[FILEGROUP_NAME] = FG.name ,[File_Location] = DF.PHYSICAL_NAME ,[FILESIZE_MB] = CONVERT(DECIMAL(10,2),DF.SIZE/128.0) ,[USEDSPACE_MB] = CONVERT(DECIMAL(10,2),DF.SIZE/128.0 - ((SIZE/128.0) - CAST(FILEPROPERTY(DF.NAME, 'SPACEUSED') AS INT)/128.0)) ,[FREESPACE_MB] = CONVERT(DECIMAL(10,2),DF.SIZE/128.0 - CAST(FILEPROPERTY(DF.NAME, 'SPACEUSED') AS INT)/128.0) ,[FREESPACE_%] = CONVERT(DECIMAL(10,2),((DF.SIZE/128.0 - CAST(FILEPROPERTY(DF.NAME, 'SPACEUSED') AS INT)/128.0)/(DF.SIZE/128.0))*100) ,[AutoGrow] = 'By ' + CASE is_percent_growth WHEN 0 THEN CAST(growth/128 AS VARCHAR(10)) + ' MB -' WHEN 1 THEN CAST(growth AS VARCHAR(10)) + '% -' ELSE '' END + CASE max_size WHEN 0 THEN 'DISABLED' WHEN -1 THEN ' Unrestricted' ELSE ' Restricted to ' + CAST(max_size/(128*1024) AS VARCHAR(10)) + ' GB' END + CASE is_percent_growth WHEN 1 THEN ' [WARNING: Autogrowth by percent]' ELSE '' END FROM sys.database_files DF LEFT JOIN sys.filegroups FG ON DF.data_space_id = FG.data_space_id order by DF.TYPE desc, DF.NAME;dba.stackovernet.com
Можете ли вы обойти ограничение размера SQL Server Express путем укладки баз данных?
Моя компания работает над проектом разработки с использованием SQL Server 2008 Express. Объем данных, которые мы планируем хранить в нашей основной таблице, быстро превысит ограничение на 4 ГБ Express. Мы можем купить себе некоторое время с SQL Server 2008 R2, но в итоге мы также превзойдем ограничение на 10 ГБ.
Руководитель команды хочет услышать все доступные варианты, прежде чем приобретать лицензии для Standard Edition. Экспертами, доступными в нашей компании, являются SQL Server и Oracle, поэтому использование MySQL или PostgresSQL будет считаться последним средством.
Единственная альтернатива, которую я могу придумать, – это дизайн, в котором главная таблица горизонтально разделена на отдельные, разные базы данных. Кроме того, будет создана центральная база данных для хранения информации о том, где хранятся данные.
Например, все данные таблицы за 2008 год будут храниться в данных DB_2008, 2009 в DB_2009 и т. Д. Таблица метаданных может выглядеть так:
Эта таблица будет использоваться для определения местоположения базы данных данных для наших хранимых процедур. Большая часть нашего кода уже использует параметризованный динамический SQL, поэтому это будет непросто реализовать.
Есть ли установленная модель для такого типа дизайна или это просто ужасная идея?
Я понимаю, что это точно не касается вашего вопроса, но, по моему опыту, всегда стоит дороже взломать неприятный клод, как это, – подумайте о долларах в час для разработки и обслуживания, плюс время, когда вы потеряли возможности разработки, которые действительно имеют значение – чтобы купить нужные инструменты в первую очередь.
EDITED: И почему стандартная версия вместо Workgroup? Если Express удовлетворяет вашим требованиям к функциям, то и Workgroup, и это на $ 3500 дешевле, чем Standard. Тем не менее, либо сделка по сравнению с седлом себя, как описано выше – вдвойне, поэтому, если вы можете лицензировать CAL, а не процессор. 🙂
Это ужасная идея. IANAL, но вы все равно можете нарушать лицензию SQL Server даже с этой схемой. Они печатали всевозможные мелкие шрифты о «мультиплексировании» и еще о многом.
Даже если у вас есть это на работе, вы вполне можете столкнуться с неприятными проблемами производительности и аутентификации, и сохранение данных будет больно. Предполагая, что ваши разработчики не работают бесплатно, покупка лицензии будет дешевле.
Не делай этого.
Единственный способ, которым я хотел бы заняться чем-то подобным, – это то, что мне гарантировано, что
- отчеты не будут пересекать эти границы, и
- при запросе данных пользователь будет ограничен текущим годом.
Реальность такова, что эти ограничения редко срабатывают. Подумайте о том, кто хочет получить 12-месячный отчет в марте, с предыдущего марша … Вам нужно будет обобщать результаты в коде.
В конце дня вы потратите LOT больше времени на разработку, выполняя эту работу, чем стандартная лицензия на sql будет стоить вам. EDIT : Я верну последнее предложение: это будет стоить больше, чем корпоративная лицензия sql.
Нет бесплатного программного обеспечения! 🙂 Даже если вы можете обойти ограничение на 10 ГБ, вы все равно будете ограничены потоком памяти 1 ГБ. С базой данных 10 ГБ, которая, скорее всего, серьезно ухудшит производительность (если только ваша рабочая нагрузка очень мала).
Обратите внимание: если у вас есть данные varbinary в вашей базе данных, вы можете сохранить это за пределами предела 10 ГБ, используя Filestream.
Это можно сделать, вы видите это в хранилищах данных и хранении документов, но это системы, в которых вам редко приходится выбирать границу (год и т. Д.). Если вам часто приходится работать с данными из нескольких разделов / баз данных, вероятно, дешевле купить лицензию, чем кодирование и поддержку многораздельной модели.
Вы видели веб-версию SQL Server? Если вы вписываетесь в свою модель лицензирования, она использует весь основной материал сервера sql (не делает зеркалирование и не может служить сервером как источник репликации, среди некоторых других ограничений), но является очень доступным.
sqlserver.bilee.com