Клиентская база данных: зачем ее собирать и как использовать. Зачем нужна база данных
Базы данных и СУБД
Введение
Каждый владелец сайта знает, что для правильного функционирования сайта нужны не только файлы с кодом страниц, но и базы данных. Для взаимодействия с базами данных используются системы управления базами данных (СУБД). В данной статье я хочу рассказать о базах данных и СУБД, о том, какие разновидности существуют, и чем они отличаются друг от друга.
База данных
База данных представляет собой определенный набор данных, которые, как правило, связаны объединяющим признаком либо свойством (или несколькими). Эти данные упорядочены, например, по алфавиту. Обилие различных данных, которые могут быть помещены в единую базу, ведет к множеству вариаций того, что может быть записано: личные данные пользователей, записи, даты, заказы и так далее. К примеру, если у вас интернет-магазин, то база данных вашего сайта может содержать прайс-листы, каталог товаров или услуг, отчеты, статистику и информацию о клиентах.
В первую очередь это удобно тем, что информацию можно быстро заносить в базу данных и так же быстро ее извлекать при необходимости. Если на заре развития web-разработки все необходимые данные нужно было прописывать в коде страницы, то теперь такая необходимость отсутствует – нужная информация может быть запрошена из базы данных при помощи скриптов. Специальные алгоритмы хранения и поиска информации, которые используются в базах данных, позволяют находить нужные сведения буквально за доли секунд – а при работе в виртуальном пространстве скорость работы ресурса важна как ничто другое.
Немаловажной является и взаимосвязь информации в базе данных: изменение одной строчки может привести к значительным изменениям других строк. Работать с данными таким образом гораздо проще и быстрее, чем если бы изменения касались только одного места в базе данных.
Однако это не значит, что база данных обязательно должна быть у каждого сайта – к примеру, если у вас сайт-визитка, и никакой новой информации вы на сайте не размещаете, то база данных вам будет попросту не нужна.
Система управления базами данных
Как можно догадаться уже из названия, система управления базами данных (или сокращенно СУБД) представляет собой программное обеспечение, которое используется для создания и работы с базами данных. Главная функция СУБД – это управление данными (которые могут быть как во внешней, так и в оперативной памяти). СУБД обязательно поддерживает языки баз данных, а также отвечает за копирование и восстановление данных после каких-либо сбоев.
Что касается классификации баз данных, то тут возможны различные варианты.К примеру, можно разделить базы по модели данных: иерархические (имеют древовидную структуру), сетевые (по своей структуре похожи на иерархические), реляционные (используются для управления реляционными базами данных), объектно-ориентированные (используются для объектной модели данных) и объектно-реляционные (некое слияние реляционного и объектно-ориентированного вида баз данных).
Либо, если деление идет по тому, где размещается СУБД, их можно разделить на локальные – вся СУБД размещается на одном компьютере, и распределенные – части системы управления базами данных находятся на нескольких компьютерах.
Файл-серверные, клиент-серверные и встраиваемые – такие названия носят СУБД, если разделить их по способу доступа к базам данных. Файл-серверные СУБД на данный момент уже считаются устаревшими; в основном идет использование клиент-серверных (СУБД, которые располагаются на сервере вместе с самой базой данных) и встраиваемых (не требующих отдельной установки) систем.
Информация, которая хранится в базах данных, не ограничивается только текстовыми или графическими файлами – современные версии СУБД поддерживают также форматы аудио и видеофайлов.
В этой статье я сделаю упор на СУБД, которые используются для хранения информации различных веб-ресурсов.
Зачем же нужны эти СУБД? Помимо основной своей функции – хранения и систематизации огромного количества информации – они позволяют быстро обрабатывать клиентские запросы и выдавать свежую и актуальную информацию.
Это касается и изменений, которые вносите вы – вместо того, чтобы менять информацию в каждом файле сайта, вы можете поменять ее в базе данных, и тогда на каждой странице сразу же будет отображена корректная информация.
Реляционные СУБД и язык SQL
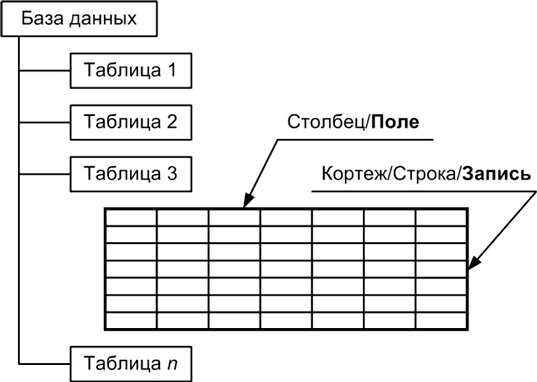
Реляционные и объектно-реляционные СУБД являются одними из самых распространенных систем. Они представляют собой таблицы, у которых каждый столбец (который называется “field” или «поле») упорядочен и имеет определенное уникальное название. Последовательность строк (их называют “records” или «записи») определяется последовательностью ввода информации в таблицу. При этом обрабатывание столбцов и строк может происходить в любом порядке. Таблицы с данными связаны между собой специальными отношениями, благодаря чему с данными из разных таблиц можно работать – к примеру, объединять их – при помощи одного запроса.
Для управления реляционными базами данных применяется особый язык программирования – SQL. Сокращение расшифровывается как “Structured query language”, в переводе на русский «язык структурированных запросов».
Команды, которые используются в SQL, делятся на те, которые манипулируют данными, те, которые определяют данные, и те, которые управляют данными.
Схема работы с базой данных выглядит следующим образом:
Далее я расскажу о каждой из основных СУБД, которые сейчас чаще всего используются при создании веб-проектов.
 MySQL
MySQL
MySQL является одной из самых популярных и распространенных СУБД, которая используется во многих компаниях (например, Facebook, Wikipedia, Twitter, LinkedIn, Alibaba и других). MySQL представляет собой реляционную СУБД, которая относится к свободному программному обеспечению: она распространяется на условиях GNU Public License. Как правило, эту систему управления базами данных определяют как хорошую, быструю и гибкую систему, рекомендованную к применению в небольших или средних проектах. У MySQL есть множество различных преимуществ. Например, она поддерживает различные типы таблиц: как известные MyISAM и InnoDB, так и более экзотичные HEAP и MERGE; кроме того, количество поддерживаемых типов постоянно растет. MySQL выполняет все команды быстро – возможно, сейчас это самая быстрая СУБД из всех существующих. С этой системой управления базами данных может одновременно работать неограниченное количество пользователей, а число строк в таблицах может быть равно 50 миллионам.
Так как в сравнении с некоторыми другими СУБД MySQL поддерживает меньшее количество возможностей, то и работать с ней значительно проще, чем, к примеру, с PostgreSQL, о которой будет рассказано ниже.
Первая версия MySQL вышла в далеком 1995 году, и с тех пор состоялось несколько последующих релизов, каждый из которых нес в себе значительные изменения.
Для работы с MySQL используется не только текстовый, но и графический режим. Это возможно благодаря приложению phpMyAdmin: для работы в приложении вам даже не нужно будет знать SQL-команды, а администрировать свою базу данных можно прямо через браузер.
В целом можно отметить, что MySQL – это выбор тех, кому необходима СУБД для проекта небольшого или среднего размера, быстрая и удобная в работе и без сложностей с администрированием.
PostgreSQL
Эта свободно распространяемая система управления базами данных относится к объектно-реляционному типу СУБД. Как и в случае с MySQL, работа с PostgreSQL основывается на языке SQL, однако, в отличие от MySQL, PostgreSQL поддерживает стандарт SQL-2011. Эта СУБД не имеет ограничений ни по максимальному размеру базы данных, ни по максимуму записей или индексов в таблице.
Если говорить о преимуществах PostgreSQL, то, безусловно, это надежность транзакций и репликаций, возможность наследования и легкая расширяемость. PostgreSQL поддерживает различные расширения и варианты языков программирования, такие как PL/Perl, PL/Python и PL/Java. Также есть возможность загружать C-совместимые модули.
Многие отмечают, что в отличие от MySQL данная СУБД имеет хорошую и подробную документацию, которая дает ответы практически на все вопросы.
О том, что это более масштабная, чем MySQL, СУБД, говорит и тот факт, что PostgreSQL периодически сравнивают с такой мощной системой управления данных, как Oracle.
Все это позволяет говорить о PostgreSQL как об одной из самых продвинутых СУБД на данный момент.
 SQLite
SQLite
На данный момент это одна из самых компактных СУБД; также она является встраиваемой и реляционной. SQLite позволяет хранить все данные в одном файле и, благодаря своему небольшому объему, отличается завидным быстродействием. SQLite значительно отличается от MySQL и PostgreSQL своей структурой: движок и интерфейс этой СУБД находятся в одной библиотеке – и именно это позволяет выполнять все запросы очень быстро. Другие СУБД (MySQL, PostgreSQL, Oracle и т.д.) используют парадигму клиент-сервер, когда взаимодействие происходит через сетевой протокол.
Из недостатков можно отметить отсутствие системы пользователей и возможности увеличения производительности.
SQLite можно посоветовать к использованию в проектах, где нужно иметь возможность быстро перенести приложение, и нет необходимости в масштабируемости.
Oracle
Эта СУБД относится к объектно-реляционному типу. Название произошло от названия разработавшей эту систему фирмы Oracle. Наравне с SQL СУБД использует процедурное расширение под названием PL/SQL, а также язык Java.
Oracle – это система, отличающаяся стабильностью уже не один десяток лет, поэтому ее выбирают крупные корпорации, для которых важна надежность восстановления после сбоев, отлаженная процедура бэкапа, возможность масштабирования и другие ценные возможности. К тому же эта СУБД обеспечивает отличную безопасность и эффектную защиту данных.
В отличие от других СУБД, стоимость покупки и использования Oracle достаточно высока, и именно это зачастую является значимым препятствием к ее использованию в небольших фирмах. Вероятно, именно это также является причиной того, что в рейтинге СУБД на 2016 год в России Oracle находится лишь на 6-м месте.
MongoDB
Эта СУБД отличается тем, что она предназначена для хранения иерархических структур данных, и поэтому ее называют документоориентированной (она представляет собой документное хранилище без использования таблиц или схем). MongoDB имеет открытый исходный код.
Используя идентификатор, вы можете производить быстрые операции над объектом; эта СУБД хорошо показывает себя и при сложных взаимодействиях. В первую очередь речь идет о быстродействии – в некоторых случаях приложение, написанное на MongoDB, будет работать быстрее, чем такое же приложение, использующее SQL, т.к. MongoDB относится к классу СУБД NoSQL и вместо SQL пользуется объектным языком запросов, который значительно легче SQL.
Однако этот язык имеет и свои ограничения, а поэтому MongoDB следует использовать в случаях, когда нет необходимости в сложных и нетривиальных выборках.
Вместо заключения
Выбор СУБД – это важный момент при создании своего ресурса. Отталкивайтесь от своих задач и возможностей, пробуйте и экспериментируйте, чтобы найти именно тот вариант, который будет наиболее подходящим.
timeweb.com
База данных - это что такое: где используется и как создается
Это устойчивое словосочетание обычно вызывает ассоциации с кино про спецслужбы. На самом деле база данных это та вещь, с которой мы сталкиваемся и в повседневной жизни довольно часто.
В широком смысле это понятие можно отнести к любой информации, которая расположена в соответствии с каким-нибудь принципом упорядоченности. Например карточки с именами и телефонами, сложенные по алфавиту. Каталог на сайте, где одежда или обувь распределены по цветам и размерам, это тоже своего рода база данных.
В цифровом мире
Однако в информатике базой данных может быть только цифровая информация, которую сможет обрабатывать и сохранять компьютер. Объекты в такой базе сгруппированы по какому-нибудь одному или нескольким общим свойствам. По этим параметрам система и отыскивает необходимое практически моментально.
Базы данных на любой вкус и цвет
Базы данных — совокупность хранимых объектов — бывают разных типов и каждый тип наиболее подходит для своей задачи. Базу иерархического типа можно изобразить в виде дерева, каждый объект в ней способен содержать в себе несколько подобъектов, но сам может быть частью только одного конкретного, вышестоящего.
Пример такой БД может увидеть каждый в своей Windows, структура папок этой операционной системы размещена именно в иерархическом порядке. Благодаря этому использование Windows очень простое в ручном режиме.
Сетевая база данных чем-то напоминает иерархическую. Её отличие в том, что каждый объект может зависеть сразу от нескольких вышестоящих. Поэтому при удалении одного объекта не произойдёт удаления зависимых от него. Такая модель БД подходит для создания программ управления финансами и их упорядочения.
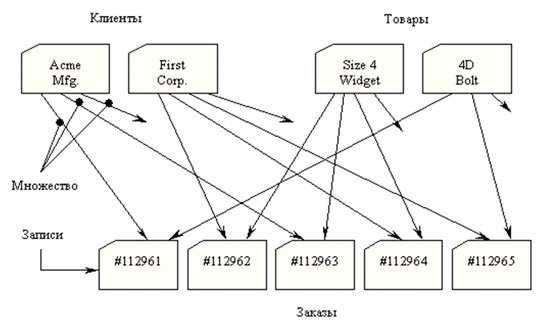
Реляционная база данных одна из самых знакомых большинству из нас. По сути это таблица, набор таблиц, где данные лежат в ячейках. А отыскать их быстро можно по параметрам столбцов и строк этих таблиц.
Визуальный пример такой базы данных висит у вас на стене. Отыскав в календаре строчку недели мы можем легко узнать, какое число будет в нужный нам день, выбрав соответствующий ему столбец.
Зачем базы данных нужны лично нам
Умение обращаться с базой данных может пригодиться в разных областях деятельности. Если у вас есть собственный сайт, управление им существенно облегчится, если создать для него собственную базу данных. Благодаря ей контент сайта можно динамически обновлять и дополнять. Станет более удобной система управления.
Крупные объёмы информации будет легче хранить и использовать. Если на вашем сайте ожидается большое количество пользователей, создание собственной базы данных упростит работу с ними. Больше полезных советов по обслуживанию сайтов можно найти в этом разделе по ссылке.
Как ими управлять
Самое распространённое средство для работы с базами данных — MySql, оно поддерживает множество языков программирования. Подходит для выполнения различных задач — для создания баз, управления ими, для выборки отдельных записей из базы.
Эта система управления может работать с разными типами баз данных. Ещё одна сторона её универсальности — возможность пользоваться практически в любой операционной системе.

Чаще всего в работе с системой mysql используют язык php. Это один из самых популярных языков программирования для создания баз данных и для построения веб-сайтов. Его особенность в том, что он подходит ко множеству систем управления базами данных.
К тому же, если правильно спланировать сайт, написанный на php, его будет легко расширять и дополнять. Благодаря динамичности этого языка ваш сайт сможет быстро развиваться, принося больше радости и дохода.

Построй свой сайт эффективно
Хочется уже попробовать сделать собственный сайт функциональным и удобным? Загляните в видеокурс по созданию сайтов средствами PHP — «PHP и MySQL с Нуля до Гуру», с его помощью новичку в этой области будет проще освоиться.

Может оказаться, что это даже станет вашим хобби или профессией. Так что попробуйте сразу это средство разработки на практике, используя рекомендации из курса.
В моём блоге вы найдёте немало других интересных статей. Не забудьте подписаться на обновления, чтобы не пропустить самые свежие посты. Из моей группы Вконтакте обновления можно получать прямо в новостную ленту своей странички, подписавшись на группу.
start-luck.ru
что это такое, преимущества перед другими СУБД

База данных сайта MySQL – это система, предназначенная для хранения и обработки информации. Комплекс таблиц, взаимосвязанных между собой, для доступа к которым применяется система управления базами данных (СУБД) MySQL. По сути, MySQL – это специальная программа с открытым кодом, которая используется на сервере SQL. Данная программа не способна обрабатывать большое количество информации, однако она идеальна для небольших и крупных веб-ресурсов.
Зачем нужна база данных?
Представьте, что вы ведете свой сайт. Если у вас небольшой статический проект, в котором содержится всего несколько html страниц, то применение базы данных(БД) вам вовсе и не нужно. Но это редкие случаи, когда создаваемые web-мастерами проекты остаются практически незаполненными. Как правило, сайты продолжают наполняться контентом, они становятся более загруженными. Такие проекты уже являются динамичными, и без базы данных вести их очень сложно.
Храня гигабайты информации, распределенной по сотням файлов, вам придется тратить уйму времени при выдаче необходимых строк в процессе функционирования сервера. Чтобы избежать этого, нужны БД, занимающиеся группировкой и упорядочиванием информации. Код для базы данных значительно проще, чем код, предназначенный с целью применения файлов. При этом запрос обрабатывается куда быстрее.
В БД все данные представлены таблицей с комментариями, информацией об объектах и т.п. Стоит отметить, что БД постоянно меняется, дополняется новыми данными, исправляется та информация, которая уже есть в ней. И чтобы не возникало трудностей в процессе администрирования, добавления и изменения информации, были придуманы специальные системы управления БД. Об одной из них мы и говорим в данной статье, так как MySQL в своей сфере пользуется наибольшим спросом.
Какими преимуществами обладает MySQL?
Одними из главных плюсов MySQL, благодаря которым программа нравится многим веб-мастерам, является высокая скорость обработки информации и функциональность СУБД. Как мы уже упоминали выше, данная система представляет собой программное обеспечение с открытым кодом, и она доступна любому пользователю абсолютно бесплатно, что тоже склоняет чашу весов в сторону MySQL. Большинство современных хостингов используют именно MySQL.
Веб-мастер получает возможность совершенствовать код и вносить в него собственные изменения, что делает программу гибкой. MySQL является лишь одним из многих программных обеспечений, работающих с SQL.
SQL – язык запросов, предназначенный для организации управления реляционными БД (со связанными между собой данными). Он многофункционален и с его помощью можно корректировать, создавать и убирать данные из таблиц, запрашивать из них информацию, создавать сами таблицы и т.д.
На заметку! В интернет-пространстве MySQL еще известна как «мускул». Такое название ей придумали веб-мастера. К примеру, когда говорят фразу «CMS на мускуле», это значит, что система управления контентом сайта (движок) применяет СУБД MySQL.
Как информация хранится в реляционных БД?
 Чтобы понять, как реляционные БД хранят различные данные, лучше всего привести в пример обычную таблицу со столбцами и строками, куда внесены имена, а также соответствующие им телефонные номера, адреса и прочая информация. Такой вид имеет и реляционная БД. В каждом столбце указано определенное название, и все содержащиеся в них значения являются однотипными переменными. Столбцы строго упорядочиваются, в отличие от строк, в которых могут содержаться значения из разных таблиц. Сделав запрос к базе данных, вам будет выдан результат в таблице.
Чтобы понять, как реляционные БД хранят различные данные, лучше всего привести в пример обычную таблицу со столбцами и строками, куда внесены имена, а также соответствующие им телефонные номера, адреса и прочая информация. Такой вид имеет и реляционная БД. В каждом столбце указано определенное название, и все содержащиеся в них значения являются однотипными переменными. Столбцы строго упорядочиваются, в отличие от строк, в которых могут содержаться значения из разных таблиц. Сделав запрос к базе данных, вам будет выдан результат в таблице.
Все значения в БД делятся на два типа:
- Уникальные.
- Неуникальные.
К первому типу относятся хостинговые договора, номера банковских карт и т.п. А к неуникальным приписывается информация, которая может повторяться, например, имя, дата рождения, время и пр. Уникальные данные содержатся в списке под названием «уникальный индекс».
Отличия MySQL от других СУБД
От других программ MySQL отличается тем, что он без проблем работает с интерфейсом API. С помощью данного программного обеспечения, юзер легко получает доступ из пользовательской программы к системе управления БД, даже если она написана на C, Perl и прочих языках программирования.
Для администрирования веб-сайтами, чаще всего используется сочетание MySQL с PHP. Большое количество движков (CMS) написаны именно на базе этой «связки». Один из таких движков известен любому начинающему web-мастеру – это система управления контентом для блогов и сайтов WordPress, получившая огромную популярность во всем мире. В вордпрессе присутствует огромное количество функций, на основе которых обеспечивается взаимодействие с MySQL, к примеру, «mysql_connect».
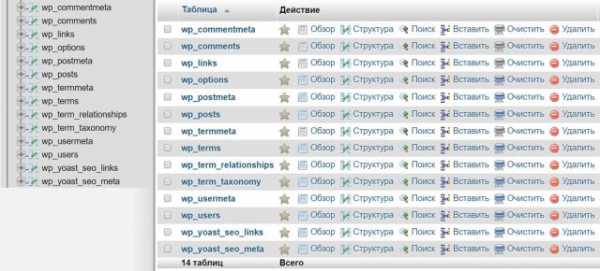
Так выглядят mysql таблицы у wordpress
Заключение
Кроме MySQL, сегодня на просторах Интернета вы можете найти огромное количество других систем управления БД, таких как PostgreSQL, mSQL и т.д. Все они обладают рядом преимуществ и недостатков, однако именно программа MySQL является самой универсальной, удобной и гибкой среди всех остальных.
webmasterie.ru
Зачем нужна денормализация баз данных, и когда ее использовать / Блог компании Латера Софтвер / Хабр

В нашем блоге на Хабре мы не только рассказываем о развитии своего продукта — биллинга для операторов связи «Гидра», но и публикуем материалы о работе с инфраструктурой и использовании технологий.
Недавно мы писали об использовании Clojure и MongoDB, а сегодня речь пойдет о плюсах и минусах денормализации баз данных. Разработчик баз данных и финансовый аналитик Эмил Дркушич (Emil Drkušić) написал в блоге компании Vertabelo материал о том, зачем, как и когда использовать этот подход. Мы представляем вашему вниманию главные тезисы этой заметки.
Что такое денормализация?
Обычно под этим термином понимают стратегию, применимую к уже нормализованной базе данных с целью повышения ее производительности. Смысл этого действия — поместить избыточные данные туда, где они смогут принести максимальную пользу. Для этого можно использовать дополнительные поля в уже существующих таблицах, добавлять новые таблицы или даже создавать новые экземпляры существующих таблиц. Логика в том, чтобы снизить время исполнения определенных запросов через упрощение доступа к данным или через создание таблиц с результатами отчетов, построенных на основании исходных данных.Непременное условие процесса денормализации — наличие нормализованной базы. Важно понимать различие между ситуацией, когда база данных вообще не была нормализована, и нормализованной базой, прошедшей затем денормализацию. Во втором случае — все хорошо, а вот первый говорит об ошибках в проектировании или недостатке знаний у специалистов, которые этим занимались.
Рассмотрим нормализованную модель для простейшей CRM-системы:
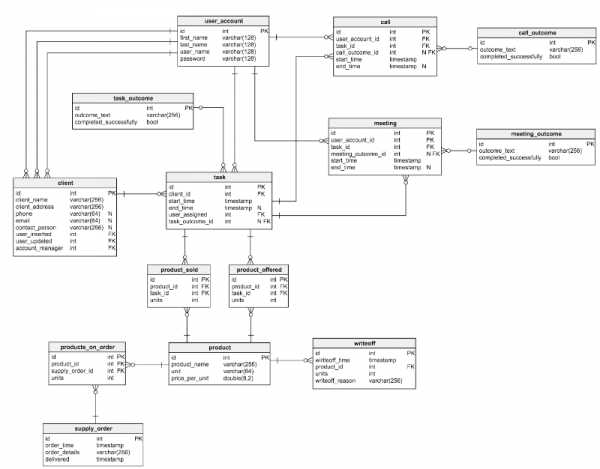
Пробежимся по имеющимся здесь таблицам:
- Таблица user_account хранит данные о пользователях, зарегистрированных в приложении (для упрощения модели роли и права пользователей из нее исключены).
- Таблица client содержит некие базовые сведения о клиентах.
- Таблица product — это список предлагаемых товаров.
- Таблица task содержит все созданные задачи. Каждую из них можно представить в виде набора согласованных действий по отношению к клиенту. Для каждой есть список звонков, встреч, предложенных и проданных товаров.
- Таблицы call и meeting хранят данные о заказах и встречах с клиентами и связывают их с текущими задачами.
- Словари task_outcome, meeting_outcome и call_outcome содержат все возможные варианты результата звонков, встреч и задания.
- product_offered хранит список продуктов, которые были предложены клиентам;
- product_sold — продукты, которые удалось продать.
- Таблица supply_order хранит информацию обо всех размещенных заказах.
- Таблица writeoff содержит перечень списанных по каким-либо причинам товаров.
Когда полезно использовать денормализацию
Прежде чем браться разнормализовывать то, что уже однажды было нормализовано, естественно, нужно четко понимать, зачем это нужно? Следует убедиться, что выгода от применения метода перевешивает возможные негативные последствия. Вот несколько ситуаций, в которых определенно стоит задуматься о денормализации.- Сохранение исторических данных. Данные меняются с течением времени, но может быть нужно сохранять значения, которые были введены в момент создания записи. Например, могут измениться имя и фамилия клиента или другие данные о его месте жительства и роде занятий. Задача должна содержать значения полей, которые были актуальны на момент создания задачи. Если этого не обеспечить, то восстановить прошлые данные корректно не удастся. Решить проблему можно, добавив таблицу с историей изменений. В таком случае SELECT-запрос, который будет возвращать задачу и актуальное имя клиента будет более сложным. Возможно, дополнительная таблица — не лучший выход из положения.
- Повышение производительности запросов. Некоторые запросы могут использовать множество таблиц для доступа к часто запрашиваемым данным. Пример — ситуация, когда необходимо объединить до 10 таблиц для получения имени клиента и наименования товаров, которые были ему проданы. Некоторые из них, в свою очередь, могут содержать большие объемы данных. При таком раскладе разумным будет добавить напрямую поле client_id в таблицу products_sold.
- Ускорение создания отчетов. Бизнесу часто требуется выгружать определенную статистику. Создание отчетов по «живым» данным может требовать большого количества времени, да и производительность всей системы может в таком случае упасть. Например, требуется отслеживать клиентские продажи за определенный промежуток по заданной группе или по всем пользователям разом. Решающий эту задачу запрос в «боевой» базе перелопатит ее полностью, прежде чем подобный отчет будет сформирован. Нетрудно представить, насколько медленнее все будет работать, если такие отчеты будут нужны ежедневно.
- Предварительные вычисления часто запрашиваемых значений. Всегда есть потребность держать наиболее часто запрашиваемые значения наготове для регулярных расчетов, а не создавать их заново, генерируя их каждый раз в реальном времени.
Не все так гладко
Очевидная цель денормализации — повышение производительности. Но всему есть своя цена. В данном случае она складывается из следующих пунктов:- Место на диске. Ожидаемо, поскольку данные дублируются.
- Аномалии данных. Необходимо понимать, что с определенного момента данные могут быть изменены в нескольких местах одновременно. Соответственно, нужно корректно менять и их копии. Это же относится к отчетам и предварительно вычисляемым значениям. Решить проблему можно с помощью триггеров, транзакций и хранимых процедур для совмещения операций.
- Документация. Каждое применение денормализации следует подробно документировать. Если в будущем структура базы поменяется, то в ходе этого процесса нужно будет учесть все прошлые изменения — возможно, от них вообще можно будет к тому моменту отказаться за ненадобностью. (Пример: в клиентскую таблицу добавлен новый атрибут, что приводит к необходимости сохранения прошлых значений. Чтобы решить эту задачу, придется поменять настройки денормализации).
- Замедление других операций. Вполне возможно, что применение денормализации замедлит процессы вставки, модификации и удаления данных. Если подобные действия проводятся относительно редко, то это может быть оправдано. В этом случае мы разбиваем один медленный SELECT-запрос на серию более мелких запросов по вводу, обновлению и удалению данных. Если сложный запрос может серьезно замедлить всю систему, то замедление множества небольших операций не отразится на качестве работы приложения столь драматических образом.
- Больше кода. Пункты 2 и 3 потребуют добавления кода. В то же время они могут существенно упростить некоторые запросы. Если денормализации подвергается существующая база данных, то потребуется модифицировать эти запросы, чтобы оптимизировать работу всей системы. Также понадобится обновить существующие записи, заполнив значения добавленных атрибутов — это тоже потребует написания некоторого количества кода.
Денормализация на примере
В представленной модели были применены некоторые из вышеупомянутых правил денормализации. Синим отмечены новые блоки, розовым — те, что были изменены.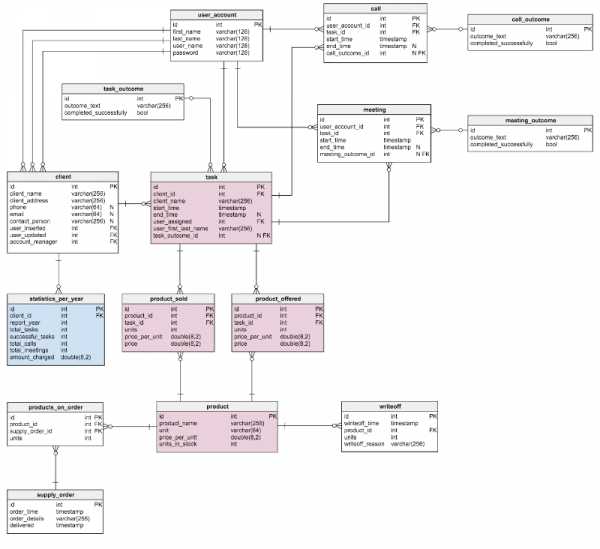
Что изменилось и почему?
Единственное нововведение в таблице product — строка units_in_stock. В нормализованной модели мы можем вычислить это значение следующим образом: заказанное наименование — проданное — (предложенное) — списанное (units ordered — units sold — (units offered) — units written off). Вычисление повторяется каждый раз, когда клиент запрашивает товар. Это довольно затратный по времени процесс. Вместо этого можно вычислять значение заранее так, чтобы к моменту поступления запроса от покупателя, все уже было наготове. С другой стороны, атрибут units_in_stock должен оновляться после каждой операции ввода, обновления или удаления в таблицах products_on_order, writeoff, product_offered и product_sold.
В таблицу task добавлено два новых атрибута: client_name и user_first_last_name. Оба они хранят значения на момент создания задачи — это нужно, потому что каждое из них может поменяться с течением времени. Также нужно сохранить внешний ключ, который связывает их с исходным пользовательским и клиентским ID. Есть и другие значения, которые нужно хранить — например, адрес клиента или информация о включенных в стоимость налогах вроде НДС.
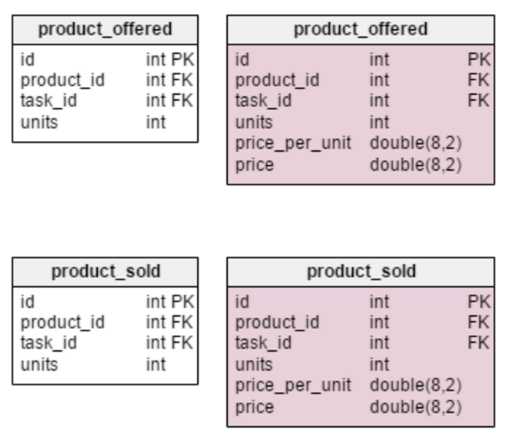
Денормализованная таблица product_offered получила два новых атрибута: price_per_unit и price. Первый из них необходим для хранения актуальной цены на момент предложения товара. Нормализованная модель будет показывать лишь ее текущее состояние. Поэтому, как только цена изменится, изменится и «ценовая история». Нововведение не просто ускорит работу базы, оно улучшает функциональность. Строка price вычисляет значение units_sold * price_per_unit. Таким образом, не нужно делать расчет каждый раз, как понадобится взглянуть на список предложенных товаров. Это небольшая цена за увеличение производительности.
Изменения в таблице product_sold сделаны по тем же соображениям. С той лишь разницей, что в данном случае речь идет о проданных наименованиях товара.
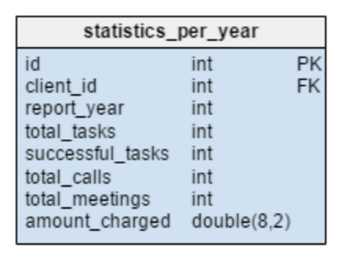
Таблица statistics_per_year (статистика за год) в тестовой модели — абсолютно новый элемент. По сути, это денормализованная таблица, поскольку все ее данные могут быть рассчитаны из других таблиц. Здесь хранится информация о текущих задачах, успешно выполненных задачах, встречах, звонках по каждому заданному клиенту. В данном месте также хранится общая сумма проведенных начислений за каждый год. После ввода, обновления или удаления любых данных в таблицах task, meeting, call и product_sold приходится пересчитывать эти данные для каждого клиента и соответствующего года. Так как изменения, скорее всего, касаются лишь текущего года, отчеты за предыдущие годы теперь могут оставаться без изменений. Значения в этой таблице вычисляются заранее, поэтому мы сэкономим время и ресурсы, когда нам понадобятся результаты расчетов.
Денормализация — мощный подход. Не то чтобы к ней следует прибегать каждый раз, когда стоит задача увеличения производительности. Но в отдельных случаях это может быть лучшим или даже единственным решением.
Однако, прежде, чем принять окончательное решение об использовании денормализации, следует убедиться в том, что это действительно необходимо. Нужно провести анализ текущей производительности системы — часто денормализацию применяют уже после запуска системы в работу. Не стоит этого бояться, однако следует внимательно отслеживать и документировать все вносимые изменения, тогда проблем и аномалий данных не должно возникнуть.
Наш опыт
Мы в Латере много занимаемся оптимизацией производительности нашей биллинговой системы «Гидра», что неудивительно, учитывая объемы наших клиентов и специфику телеком-отрасли.Один из примеров в статье предполагает создание таблицы с промежуточными итогами для ускорения отчетов. Конечно, самое сложное в этом подходе — поддерживать актуальное состояние такой таблицы. Иногда можно переложить эту задачу на СУБД — например, использовать материализованные представления. Но, когда бизнес-логика для получения промежуточных результатов оказывается чуть более сложной, актуальность денормализованных данных приходится обеспечивать вручную.
«Гидра» имеет глубоко проработанную систему привилегий для пользователей, операторов биллинга. Права выдаются несколькими способами — можно разрешить определенные действия конкретному пользователю, можно заранее подготовить роли и выдать им разные наборы прав, можно наделить определенный отдел специальными привилегиями. Только представьте, насколько медленными стали бы обращения к любым сущностям системы, если бы каждый раз нужно было пройти всю эту цепочку, чтобы убедиться: «да, этому сотруднику разрешено заключать договоры с юридическими лицами» или «нет, у этого оператора недостаточно привилегий для работы с абонентами соседнего филиала». Вместо этого мы отдельно храним готовый агрегированный список действующих прав для пользователей и обновляем его, когда в систему вносятся изменения, способные на этот список повлиять. Сотрудники переходят из одного отдела в другой намного реже, чем открывают очередного абонента в интерфейсе биллинга, а значит вычислять полный набор их прав нам приходится настолько же реже.
Конечно, денормализация хранилища — это только одна из принимаемых мер. Часть данных стоит кэшировать и непосредственно в приложении, но если промежуточные результаты в среднем живут намного дольше, чем пользовательские сессии, есть смысл всерьез задуматься о денормализации для ускорения чтения.
Другие технические статьи в нашем блоге:
habr.com
зачем ее собирать и как использовать
Задумав создать программу лояльности, с чего вы начнете? Некоторые сначала придумывают, какие скидки и подарки будут предлагать, всерьез не задумавшись, кому и зачем предназначены эти бонусы. Суть любой программы лояльности в том, чтобы создать и удержать постоянного клиента. Насколько хорошо вы их знаете? Это показывает база данных ваших клиентов.
Клиентская база нужна любой организации, будь то маленькое домашнее кафе или крупный авиаперевозчик. Постоянные клиенты — это ценнейший актив, который многие недооценивают. Если у вас есть возможность какого-либо статистического подсчета, попробуйте посчитать, сколько денег вы зарабатываете на постоянных клиентах, а сколько вам приносят новые. Если вы — не владелец конторы по предоставлению ритуальных услуг, то, скорее всего, больше половины доходов вы получаете от клиентов, которые приходили к вам больше двух раз.
Вкладывая огромные суммы в рекламу, некоторые бизнесмены забывают, что под рукой уже есть постоянные клиенты, стабильная коммуникация с которыми нужна в первую очередь. В среднем, привлечение нового клиента обходится в 5-7 раз дороже, чем удержание постоянного. Это только в денежном выражении, а сколько на это уйдет времени и сил? Но для того, чтобы работать с постоянным клиентом, необходимо узнать, кто же этот клиент. Поэтому для начала нужно организовать сбор данных.
Сбор данных
Даже если вы — владелец крохотного кафе и просто помните в лицо своих постоянных клиентов, то это уже сбор данных. Но чем крупнее организация, тем ответственнее должен быть подход к созданию клиентской базы.
Самым простым и доступным способом составить базу клиентов является бумажное анкетирование. Такие листочки с вопросами можно просто подсунуть клиенту вместе с чеком или счетом, в надежде, что он обратит внимание и уделит Вам свое время, а можно предложить заполнить форму в обмен на дисконтную карту.
Автоматический сбор данных о клиенте — более современный и удобный способ создания клиентской базы, а также — мощный инструмент для ее анализа. Когда клиент вводит информацию о себе в электронном виде (например, в мобильном приложении от «Фабрики лояльности»), то она собирается в общую базу, которую можно изучить на характер вашей аудитории или выбрать нужных клиентов для маркетинговых действий.
Анкеты клиента в крупных организациях могут содержать множество вопросов: от половой принадлежности до вкусовых пристрастий. Важно не перегнуть палку и не утомить клиента вопросами, вызвав негативную реакцию. В любом случае, самое важное, что вы должны знать, — кто ваш клиент и как с ним связаться. Не всегда стоит спрашивать сразу и номер телефона, и электронный ящик, и почтовый адрес. Чаще всего достаточно одного канала связи. А уже после того, как вы завоюете лояльность клиента, можно узнать его День Рождения, возраст и т.д.
Зачем все это нужно?
1. Во-первых, проанализировав свою клиентскую базу, вы сможете четко определить свою целевую аудиторию, и уже основываясь на этом, сделать свою рекламную кампанию более таргетированной. То есть, зная портрет своего постоянного клиента, вы будете знать, как лучше привлекать новых.
Простейший пример: вы — владелец ресторана восточной кухни. Вы потратили много денег и сил на рекламу своего заведения: печатали и раздавали флаеры, согласовали и поставили стенд-«раскладушку», разместили в местном журнале статью о своем заведении… Но потом, проанализировав свою целевую аудиторию, обнаружили, что это — молодые люди от 18 до 25 лет. И тогда оказывается, что нужно было просто разместить рекламу в социальных сетях, и отклик на такую рекламу был бы в разы выше.
2. Второе преимущество клиентской базы: при определенном техническом оснащении вы сможете регулярно собирать отзывы своих клиентов. Делать это можно, например, с помощью электронных почтовых рассылок. Безусловно, не стоит рассчитывать на то, что все клиенты тут же с радостью вступят с вами в переписку. Но даже если 10% выскажут вам свое мнение, можно будет делать какие-то выводы.
Более простой и не требующий затрат способ организовать приток отзывов — при помощи специального сервиса в мобильном приложении бизнеса. Когда клиент пользуется бонусной картой в телефоне, ему предлагается оценить обслуживание по 5-балльной шкале, а также оставить свой комментарий. Все замечания и пожелания автоматически отправляются владельцу бизнеса, который может оперативно отреагировать на негативный отзыв и спасти репутацию своего бизнеса.
3. Третье, это, конечно же, поощрения, о которых шла речь в самом начале. Зная минимальные сведения о своих клиентах, вы сможете поздравлять их с праздниками, выдавая специальные скидки, делая эксклюзивные предложения именно тогда, когда клиенту это может быть актуально. Таким образом вы не навязываете ему свои услуги, а предлагаете их в качестве помощи в нужный момент.
Чаще всего базу данных клиентов используют для рекламных рассылок — по электронной почте или, что еще хуже, через SMS-сообщения. Нужно понимать, что спам, в любом его виде, даже если это письма на физический адрес, в неумеренных количествах вызывает обратную реакцию. И вместо того, чтобы поддержать лояльного клиента, вы можете его просто потерять навсегда. Поэтому стоит задуматься над тем, как предлагать свои услуги клиентам так, чтобы они были действительно замотивированы ими воспользоваться. Ну и напоследок, не нужно забывать, что любая клиентская база теряет в среднем около 20% в год, поэтому ее нужно постоянно пополнять и поддерживать. Для этого и существуют программы лояльности.
loyaltyplant.com
Зачем нужны базы данных MSQL? — сайт на PHP своими руками
Зачем нужны базы данных MSQL, база данных MSQL, системы баз данных
p align=»left»>Практически ни один серьезный проект в интернете не обходится без хранения информации в базе данных. А самая доступная и к тому же бесплатная — база данных MSQL. И если создание простых сайтов, которые основаны только на файловой системе, могут обойтись без базы данных, то любой движок сайта использует MSQL. Почти все программы для обслуживания веб-проекта основаны на взаимодействии с базами данных.
Если начать с простых проектов, то все скрипты регистраций и авторизаций намного удобней создавать с использованием хранения информации в базах, что максимально упрощает обслуживание самого проекта. Также все программы системы комментариев, гостевых книг и форумов трудно себе представить без использования баз данных MSQL. Просто создав такую систему, можно один раз настроить сайт, в котором сделать вывод одной информации, которая постоянно обновляеться в нужных местах страниц, и не нужно будет постоянно изменять код на страницах. Например создавать карту сайта с выводом информации из таблиц, которые вмещают в себя страницы, можно забыть о редактировании карты, она сама будет обновлятся по мере добавления информации в базу MSQL. Также работу админки сайта очень трудно себе представить без подобной функции… А самое главное, современные сайты, созданные на основе движков, полностью построены на базовой системе, по данной причине обязательно нужно разобраться в вопросе — что такое база данных?
Конечно можно все спрограммировать на файлах и всю информацию записывать в текстовые файлы, но это будет давать большую нагрузку на сервер, при одновременном посещении сайта большим количеством пользователей, что принесет большие неудобства! Хотя такие текстовые файлы также можно сложить в одну папку и это будет также база данных…
Выводом написанного будет одно:
Использование файловой системы менее эффективно при разработке серьезных проектов.А в модулях с использованием запросов из базы данных, в разы увеличивается быстрота управления контентом, а также при большой посещаемости уменьшается нагрузка на сервер, что очень не маловажно и естественно увеличивается защищенность самого сайта, а это уже в некоторых моментах играет решающую роль в жизни сайта.
В последующих постах будут описаны некоторые основные моменты, с которыми обычно сталкиваются при изучении баз данных. Потому что не секрет, что думая что знаешь все и бывает зависнешь на простом запросе, в котором проблемой будет какой то сторонний фактор, например неправильная кодировка, или пропущенный символ. Практически все с чем сталкиваются начинающие разработчики можно уложить в десяток постов, чем можно и заняться.
kapon.com.ua
database - Зачем нужна временная база данных?
Подумайте о своем дневнике о назначении/журнале - он будет проходить с 1 января по 31 декабря. Теперь мы можем запросить дневник для встреч/записей журнала в любой день. Это упорядочение называется допустимым временем. Однако встречи/записи обычно не вставляются в порядке.
Предположим, я хотел бы знать, какие встречи/записи были в моем дневнике 4 апреля. То есть все записи, которые были записаны в моем дневнике 4 апреля. Это время транзакции.
Учитывая, что встречи/записи могут быть созданы и удалены и т.д. Типичная запись имеет начальное и конечное действительное время, которое охватывает период записи и время начала и окончания транзакции, которое указывает период, в течение которого запись появилась в дневник.
Эта схема необходима, если дневник может подвергнуться исторической ревизии. Предположим, что 5 апреля я понимаю, что назначение, которое у меня было 14 февраля, действительно произошло 12 февраля, т.е. я обнаружил ошибку в своем дневнике - я могу исправить ошибку, чтобы корректировать правильное временное изображение, но теперь мой запрос того, что было в дневнике 4 апреля было бы неправильно, ЕСЛИ, время транзакций для встреч/записей также сохраняется. В этом случае, если я запрошу свой дневник по состоянию на 4 апреля, он покажет назначение, которое существовало 14 февраля, но если я попрошу по состоянию на 6 апреля, он назначит встречу 12 февраля.
Эта временная функция временной базы данных позволяет записывать информацию о том, как исправляются ошибки в базе данных. Это необходимо для достоверной проверки данных, которые записываются при внесении изменений, и позволяет запрашивать запросы, касающиеся того, как данные были пересмотрены время.
Большинство бизнес-информации должны храниться в этой битпоральной схеме, чтобы обеспечить достоверную аудиторскую запись и максимизировать бизнес-аналитику - отсюда необходимость поддержки в реляционной базе данных. Обратите внимание, что каждый элемент данных занимает (возможно неограниченный) квадрат в двумерной модели времени, поэтому люди часто используют индекс GIST для реализации битемпорального индексирования. Проблема здесь в том, что индекс GIST действительно предназначен для географических данных, а требования к временным данным несколько отличаются.
Ограничения исключения PostgreSQL 9.0 должны обеспечивать новые способы организации временных данных, например. транзакция и действительное время. ПЕРИОДЫ не должны перекрываться для одного и того же кортежа.
qaru.site