Установка ms sql 2018, ерудити. Установка ms sql 2018
Установка ms sql 2018, ерудити
Повинна з'явитися форма як на малюнку вище.
Review hardware and software requirements - дозволяє перевірити сумісність програмного і апаратного забезпечення до встановленої версією MS SQL
Install SQL Server Upgrade Advisor - встановлює утиліту для поновлення більш старого MS SQL Server до новішого.
Server components, tools, Books Online, and samples - встановлює додаткові компоненти
Run the SQL Native Client Installation Wizard - встановлювати SQL Server
Browse this CD - Огляд вмісту диска, файлів і папок
Visit the SQL Server website - перехід на домашню сторінку MS SQL
Для запуску інсталяції MS SQL Server натисніть «Run the SQL Native Client Installation Wizard»
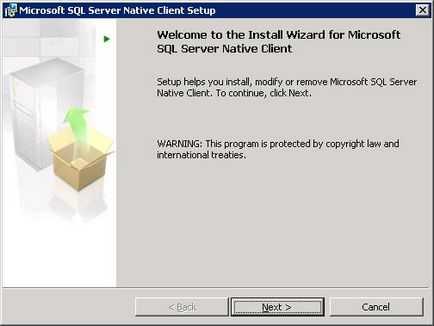
Натисніть кнопку «Next»
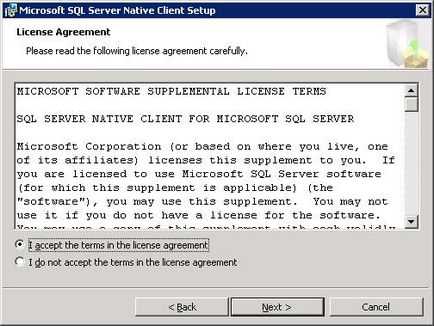
Потім виберіть «I accept the terms in the license agreement» - Для продолженія.нажміте «Next».
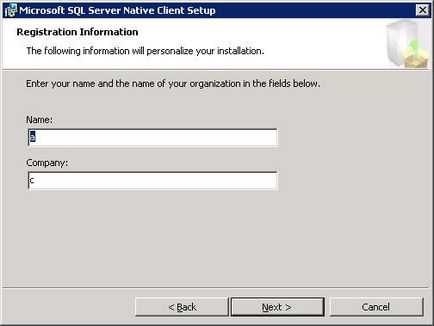
Назва організації та компанії
Заповніть поля «Name» і «Company». на свій розсуд і натисніть кнопку «Next».
Далі вам пропонують встановити «Client Components» і не встановлювати «SQL Server Native Client SDK» (документацію по SQL Server Native Client).
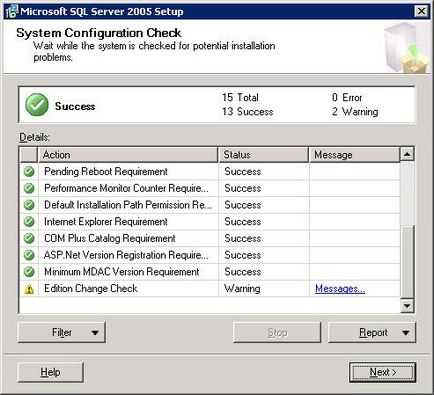
Вибір компонентів для установки MS SQL Native Client
Для того що б встановити документацію необхідно клікнути по трикутнику біля напису «SQL Server Native Client SDK»
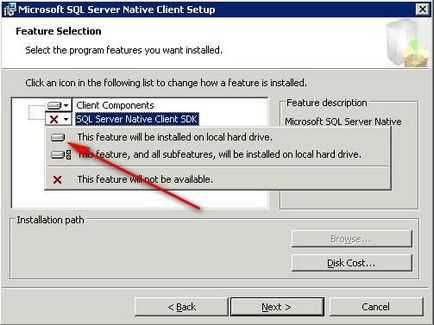
Додати компонент MS SQL Native Client в установку
І вибрати пункт «This feature will be installed on local hard drive». Для продовження натисніть кнопку «Next».
Для того що б перевірити чи достатньо у вас місця на жорсткому диску натисніть кнопку «Disk Cost». На екрані з'явитися форма на якій буде відображено кількість вільного місця на логічних дисках. Для продовження натисніть кнопку «Next».
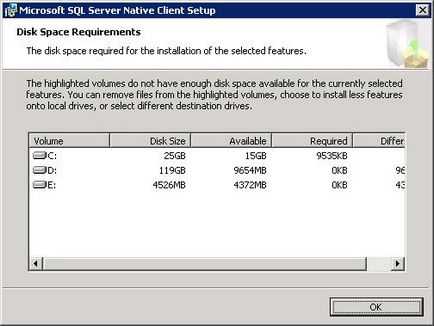
доступне місце на жорсткому диску для установки
Після цього на крані з'явитися форма, на якій необхідно прийняти остаточне рішення про встановлення MS SQL Server. Для того що б змінити параметри установки клікніть кнопку «Back». для скасування установки «Cancel», для початку установки натисніть кнопу «Install».
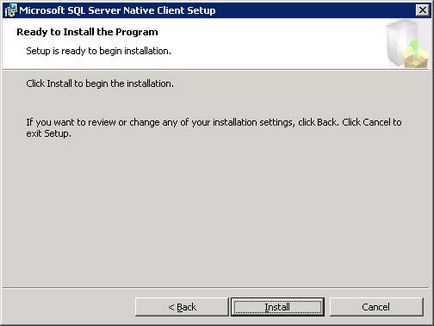
Підтвердження початку установки MS SQL Native Client
Після успішної установки на екрані з'явитися повідомлення про успішне завершення установки
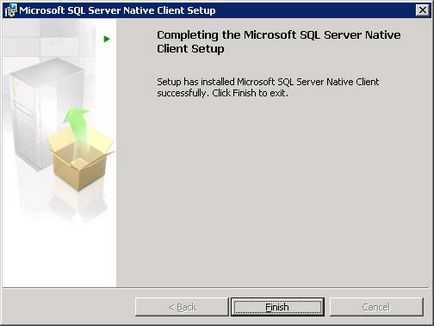
Підтвердження успішної установки MS SQL Native Client
Для запуску інсталяції додаткових служб і документації натисніть «Server components, tools, Books Online, and samples».
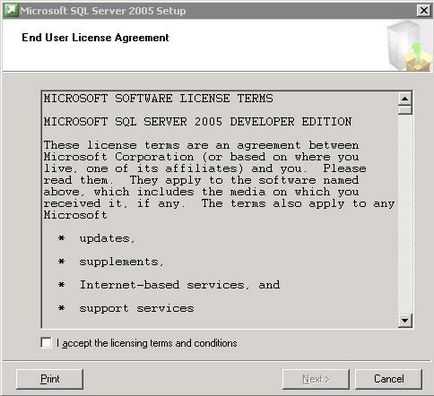
інсталяція додаткових служб і документації MS SQL Server
На формі встановіть прапорець - «I accept the licensing terms and conditions». Для продовження натисніть кнопку «Next».
Будуть встановлені необхідні компоненти
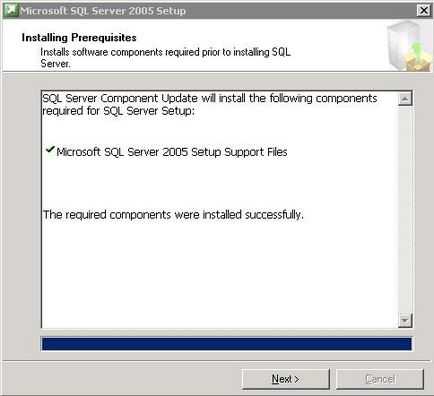
Попередня перевірка компонентів MS SQL Server
натисніть кнопку «Next». Далі з'явитися запрошення до установки
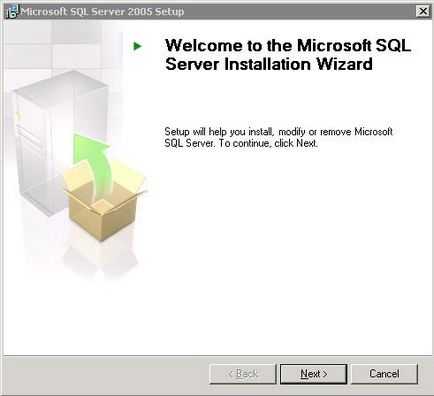
Для продовження натисніть кнопку «Next».
Після цього буде перевірена система на сумісність і будуть виведені результати перевірки.
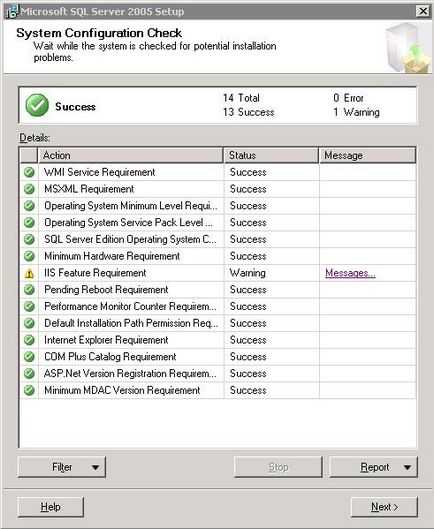
Результати перевірки можна відфільтрувати за допомогою кнопок «Filter». можна зберегти за допомогою кнопки «Report». для отримання довідки натисніть кнопку «Help». Якщо перевірка не показала сумісність з будь-яким компонентом, то у відповідній рядків е буде встановлено знак оклику і напис «Messages» - клікнувши по якій ви можете побачити деталі не сумісності. Для продовження натисніть кнопку «Next». На формі, що з'явилася необхідно ввести «Company», «Name» і ліцензійний ключ.
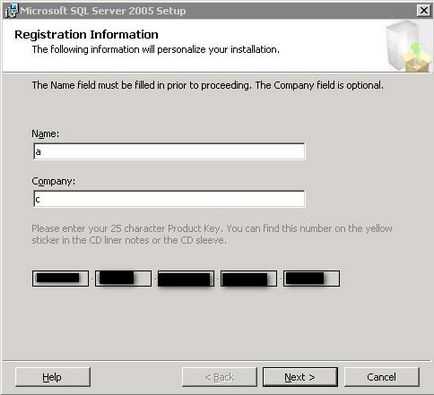
Для продовження натисніть кнопку «Next». У вікні необхідно вибрати компоненти для установлення.
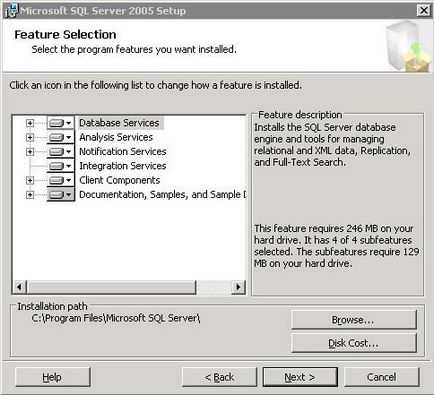
Database Engine - основна служба, яка забезпечує зберігання, обробку і захист даних. Компонент Database Engine забезпечує керований доступ і швидку обробку транзакцій, достатню навіть для найвибагливіших до наданих даними додатків. Компонент Database Engine надає багаті можливості для підтримки стабільно високого рівня доступності.
Analysis Services - багатовимірні дані дозволяють проектувати, створювати і управляти багатовимірними структурами, які містять деталізують і статистичні дані з декількох джерел даних, таких як реляційні бази даних, в одній уніфікованої логічної моделі, підтримуваної вбудованими засобами проведення обчислень.
Integration Services - включають в себе широкий набір вбудованих завдань і перетворень, засоби для побудови пакетів, а також службу Integration Services для виконання пакетів і управління ними.
Notification Services - представляють собою платформу для розробки і розгортання додатків, які формують і відправляють повідомлення.
Workstation components, Books online and development tools - встановлює додаткову документацію і інструменти розробки.
Виберіть необхідні компоненти для установки. Так само існую більш розширені можливості установки. На формі можна відмовитися від установки деяких елементів компонентів. Для цього клікніть по трикутнику біля компонента і виберіть пункт «Entire feature will be unavailable»
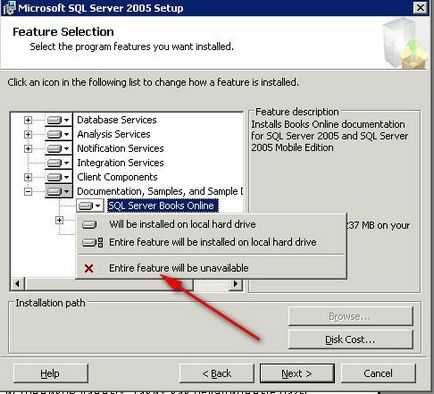
Наступного форми можна вибрати ім'я створюваного примірника SQL Server.
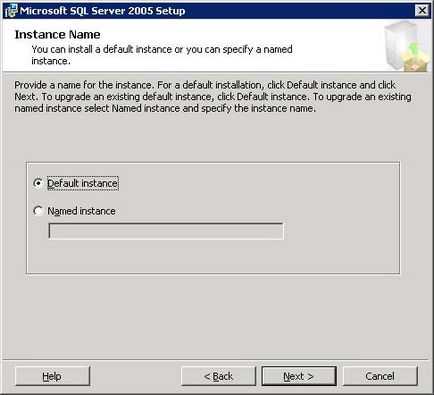
Для продовження натисніть «Next». Поле чого буде запропонована форма вибору облікового запису, справами якої будуть стартувати службу MS SQL Server
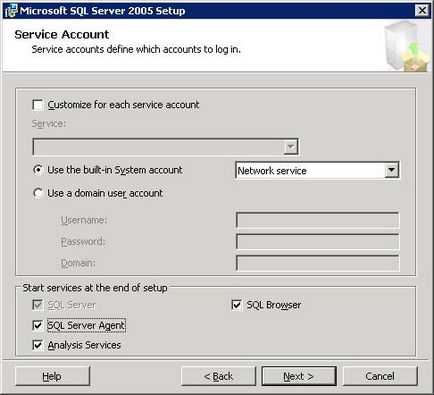
Налаштування облікового запис запуску служби
Для кожної служби можна буде налаштувати окремо. для цього встановіть прапорець "Customize for each service account". після чого буде доступний список, що випадає, в якому треба буде вибирати яка саме служба буде налаштовуватися. На цій же формі можна вибрати які служби будуть запущені після завершення установки. Це буває корисно, якщо ви не хочете після установки перезавантажувати комп'ютер (не важливо з яких причин.). після того як будуть налаштовані служби. Я рекомендую вибирати «use the build - in System account» - і вибрати зі списку «Local System» якщо у вас немає домену та Active Directory. «Network Service» - якщо є домен і необхідно буде встановити користувача з Active Directory. Крім того можна явно задати користувача, з правами якого будуть запускатися служби MS SQL Server. Для цього виберіть «use a domain user account» вказавши користувача пароль і домен. Для продовження натисніть кнопку «Next». На наступній формі
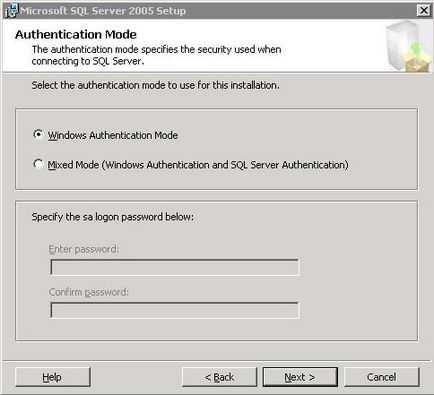
пропонується вибрати спосіб підключення до баз даних встановлюється за умовчанням SQL Server.
Якщо залишити обраної «Windows authentication Mode» - то підключення до бази можна буде виконати лише використовуючи облікові записи локального комп'ютера і Active Directory. Я рекомендую вибирати «Mixed Mode (Windows authentication and SQL Server Authentication)». Оскільки в цьому випадку можна явно задати пароль для пользователяSA - найголовнішого користувача для екземпляра SQL Server - Цей користувач має повний набір прав. Тому важливо не тільки поставити йому пароль, а й запам'ятати його. Для продовження натисніть кнопку «Next». Успадковує формі необхідно вибрати спосіб порівняння, який буде застосовувати за замовчуванням до всіх баз для даного екземпляра SQL Server.
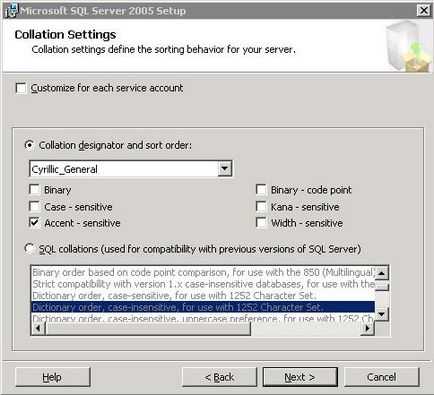
Метод порівняння буде використовуватися під на екземплярі SQL Server
За замовчуванням дані беруться з локалізації комп'ютера, на якому відбувається установка SQL Server. Несли ви не володієте заздалегідь відомими параметрами краще нічого не міняйте. Для продовження натисніть кнопку «Next».
На екрані з'явитися форма підтвердження інсталяції додаткових компонентів.
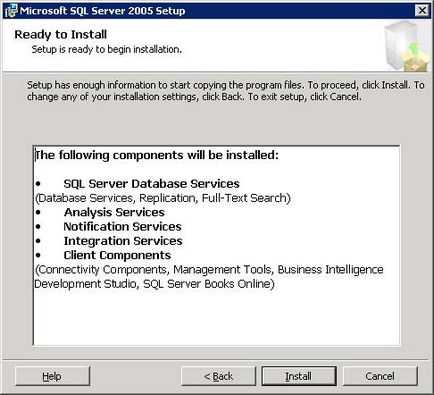
Для установки натисніть кнопку «Install». для скасування установки натисніть «Cancel». для зміни конфігурації налаштування установки SQL Server, натисніть кнопку «Back». Після початку процесу інсталяції на екрані з'явитися вікно показує поточний статус процесу установки. На цьому етапі так само можна скасувати установки натисніть «Cancel». Після того як буде завершено процес установки на екрані буде відображено звіт для про встановлення SQL Server
установка необхідних компонентів Ms SQL server
Для продовження натисніть «Next», на екрані відобразиться ще одна форма звіту про встановлення SQL Server і підтвердження завершення. Для підтвердження натисніть «Finish». Після чого рекомендується перезавантажити комп'ютер.
Ще цікаві записи з даної теми
Схожі статті
jak.bono.odessa.ua
Пошаговое развертывание AlwaysOn - MS SQL 2012
До появления Microsoft SQL Server 2012 и механизма AlwaysOn, администраторы БД имели только одну не совсем удобную технолонию зеркалирования баз данных в SQL Server от Microsoft (Database Mirroring). Причем (как показала практика тестирования, и об этом не написано в документации) - это НЕ синхронная репликация базы и логов транзакций.
Если вкратце - то мы изучали поведение базы данных при интенсивной записи и различных неисправностях. Какие сбои мы смотрели:
- Штатное выключение мастер-сервера без уведомления зеркального сервера.
- Нештатное выключение мастер-сервера.
Как ни странно, именно штатное выключение показало, что есть некоторое различие между зеркалируемыми базами.
Поэтому я бы не советовал использовать Database Mirroring в продуктивных решениях, а обратил бы внимание на технологию AlwaysOn.
Вкратце об AlwaysOn
SQL 2012 AlwaysOn - удобное решение, обеспечивающее отказоустойчивость базы данных без необходимости иметь Shared Storage. Настройка AlwaysOn достаточно проста, и на самом деле большая часть работы заключается в настройке Failover Cluster на базе Windows 2008 R2/2012. Ведь именно с этих операционных систем появилась возможно строить кластеры с сетевой папкой (Witness Share) для обеспечения кворума.
Аналогичное решение вы уже могли попробовать при работе с Exchange 2010/2013/2016 - Database Availability Group (DAG). Как видите, даже название намекает (AlwaysOn Availability Group) - по сути, это одно и то же.
Обратите внимание на требования для работы AlwaysOn:
- Вам будет нужна редакция SQL Server 2012 Enterprise.
- Windows Server Failover Cluster (WSFC) - решение работает на базовой функции Windows Server.
- Одинаковая кодировка на уровне SQL-сервера для всех участников группы доступности.
Устанавливаем Failover Cluster для SQL 2012 AlwaysOn
- В первую очередь, надо установить компонент для операционной системы - WSFC (Windows Server Failover Cluster). Ничего сложного нет, идем в обычную оснастку Server Manager и устанавливаем эту Feature. Никаких подводных камней или особенностей тут нет. Эту службу устанавливаем на оба сервера.
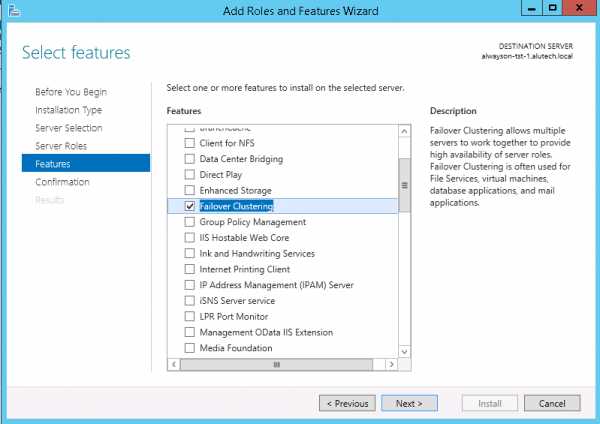
- Настраиваем теперь сам кластер. Запустите Failover Cluster Manager из консоли Server Manager.
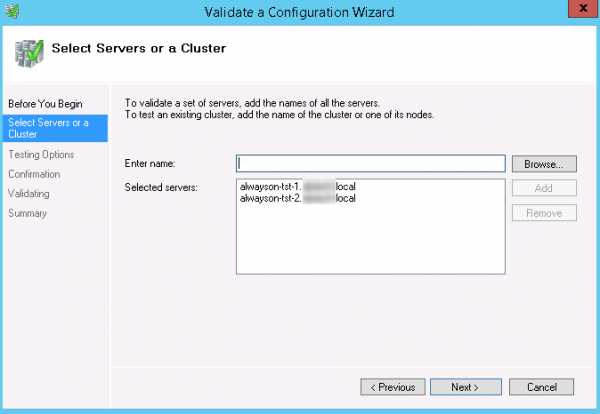
- В оснастке Failover Cluster Manager нажмите ссылку\кнопку Validate Configuration… (она есть в разных местах - точно найдете).
- На шаге мастера Select Servers or a Cluster добавляем два наших сервера, которые мы будем конфигурировать как реплики.
- На шаге Testing Options выбираем Run all tests (recommended).
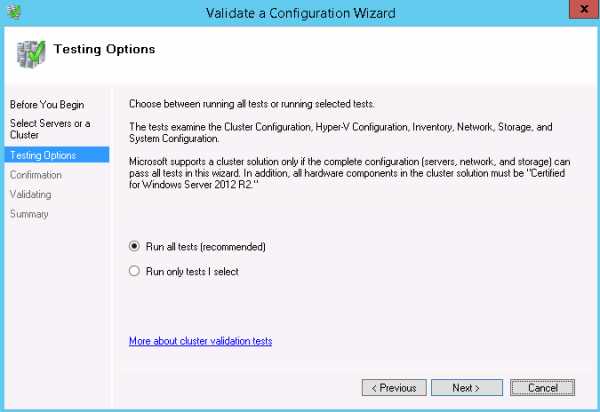 В результатах тестирования вы скорее всего получите предупреждения касательно сетевых настроек и разделяемого хранилища. Предупреждение о сетевых настройках говорит о том, что у вас нет выделенных интерфейсов для работы кластера. В принципе, ничего страшного здесь нет. По поводу разделяемого хранилища (Shared Storage) - тоже не стоит беспокоиться, т.к. мы будем использовать сетевую папку.
В результатах тестирования вы скорее всего получите предупреждения касательно сетевых настроек и разделяемого хранилища. Предупреждение о сетевых настройках говорит о том, что у вас нет выделенных интерфейсов для работы кластера. В принципе, ничего страшного здесь нет. По поводу разделяемого хранилища (Shared Storage) - тоже не стоит беспокоиться, т.к. мы будем использовать сетевую папку.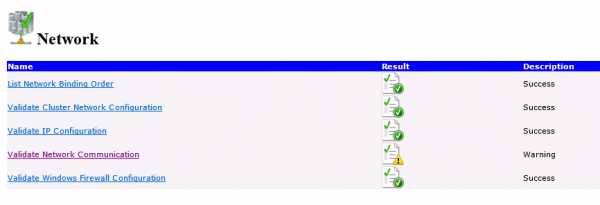
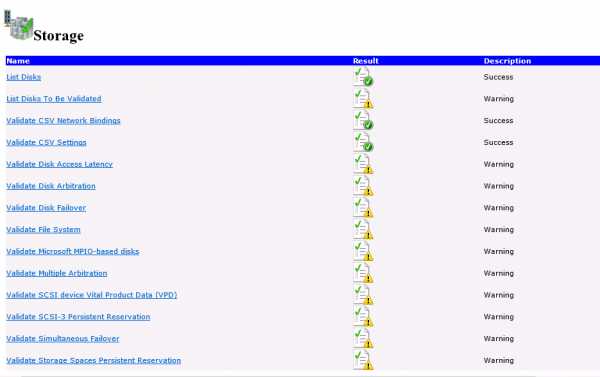
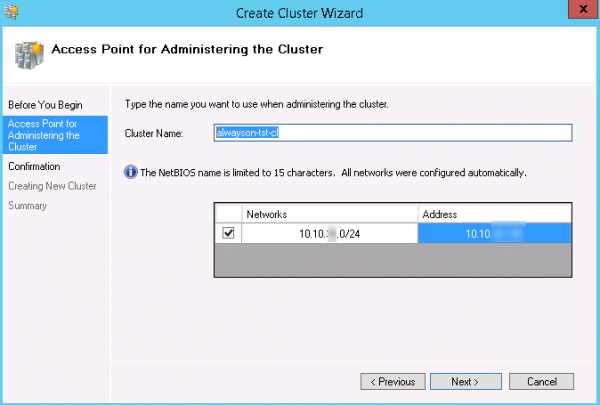 Имя кластера, которое вы тут укажете, НЕ нужно самостоятельно прописывать в DNS. Мастер настройки сделает это самостоятельно, а также самостоятельно создаст объект компьютера в Active Directory. Если вы сделаете это заранее вручную - то получите ошибку при создании кластера.
Имя кластера, которое вы тут укажете, НЕ нужно самостоятельно прописывать в DNS. Мастер настройки сделает это самостоятельно, а также самостоятельно создаст объект компьютера в Active Directory. Если вы сделаете это заранее вручную - то получите ошибку при создании кластера.- На шаге Confirmation снимите чекбокс Add all eligible storage to the cluster и нажмите Next.
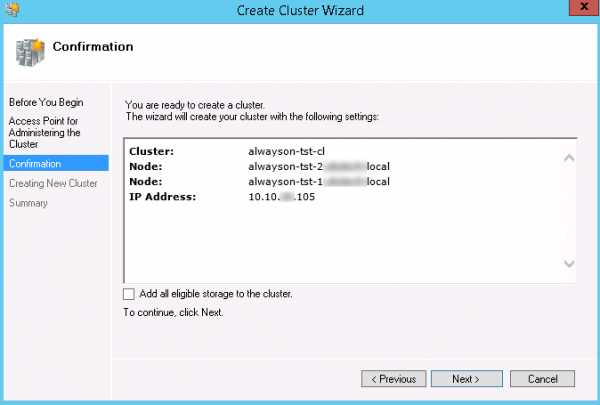 После создания кластера вы увидите еще одно предупреждение о том, что для кластера не настроен диск-свидетель. Ничего страшного, мы совсем скоро настроим сетевую папку в качестве свидетеля для кворума.
После создания кластера вы увидите еще одно предупреждение о том, что для кластера не настроен диск-свидетель. Ничего страшного, мы совсем скоро настроим сетевую папку в качестве свидетеля для кворума.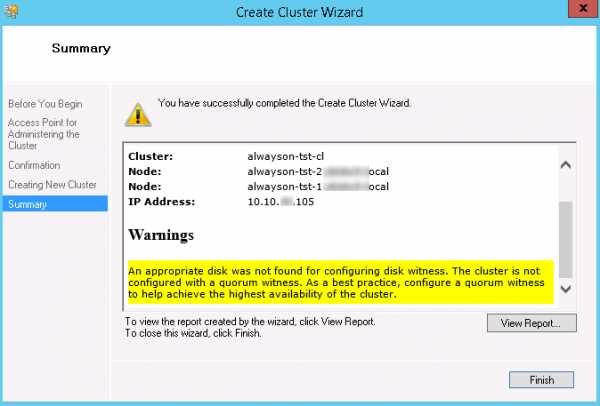
- Приступаем к настройке свидетеля. Запускаем Failover Cluster Manager, открываем наш новый кластер, выбираем More Actions и далее выбираем Configure Cluster Quorum Settings….
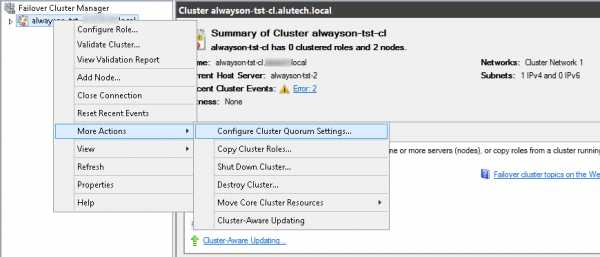
- Запускается мастер Configure Cluster Quorum. Жмем Select the quorum witness.
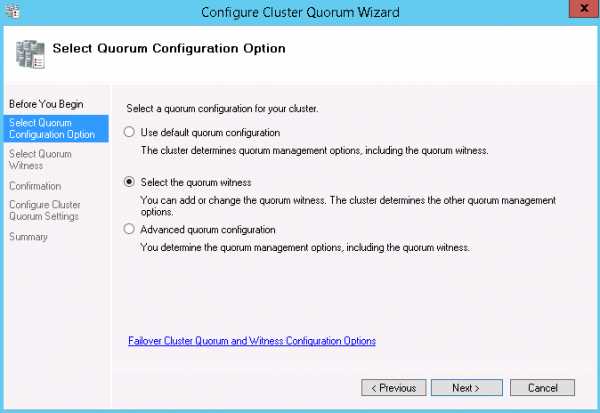
- Выбираем тип свидетеля - сетевая папка.
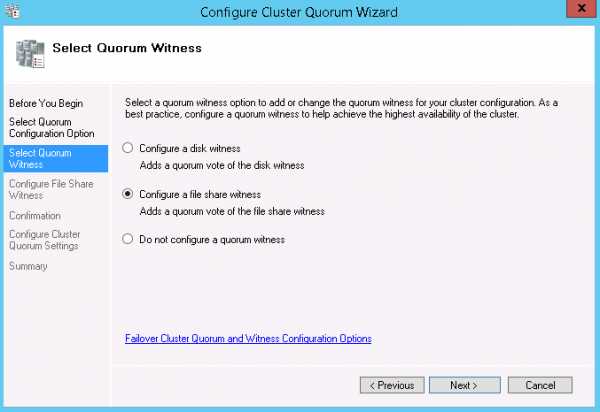
- Указываем путь к нашей папке. Тут надо отдельно сказать о том, что папку вы должны создать самостоятельно. Папка должна находится на 3-м сервере, который не является членом кластера.
Сетевые разрешения выставляем такие: Everyone - Full Access.Разрешения NTFS должны включать: пользователя, который запустил мастер настройки кластера, а также объекты компьютеров - кластера и его членов. В нашем случае это: alwayson-tst-1, alwayson-tst-2, alwayson-tst-cl.
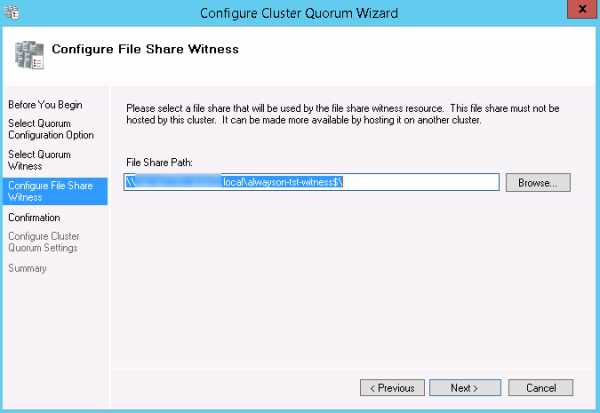
- Проверьте настройки на шаге Confirmation и нажмите Next.
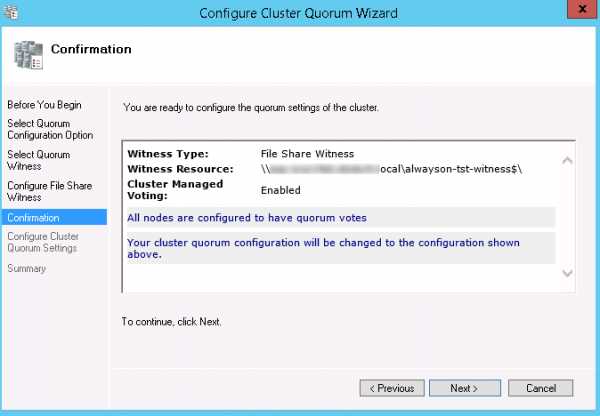 Поздравляю, кластер создан, свидетели настроены. Можете просмотреть настройки и статус, убедиться, что все зелененькое.Далее переходим к созданию группы доступности AlwaysOn.
Поздравляю, кластер создан, свидетели настроены. Можете просмотреть настройки и статус, убедиться, что все зелененькое.Далее переходим к созданию группы доступности AlwaysOn.
Создание AlwaysOn Availability Group
Перед тем как мы начнем, вы конечно установите MS SQL Server 2012. Обязательно убедитесь, что для служб SQL-сервера на каждом сервере созданы отдельные служебные учетные записи и службы работают от имени этих учетных записей. Если вы уже установили сервера и они работают из-под системных учетных записей (System), то придется переделывать. Легче всего - переустановить. Если это невозможно, обратите внимание на мою статью об этой задаче: Изменение сервисной учетной записи для MS SQL Server 2012 и последующие трудности.
Если вы этого не сделаете, то на шаге 5 (Specify Replicas) вы получите вот такое предупреждение:
А если вы нажмете Yes, то на этапе создания группы и добавления базы данных в группу, получите ошибку присоединения базы: "Joining <availability database> to availability group <availability group> at <replica>.".
Что ж, начем.
- Включаем поддержку AlwaysOn на SQL-серверах. Открываем SQL Server Configuration Manager, и в свойствах службы сервера выбираем чекбокс Enable AlwaysOn Availability Groups. После этого перезагружаем службы SQL.
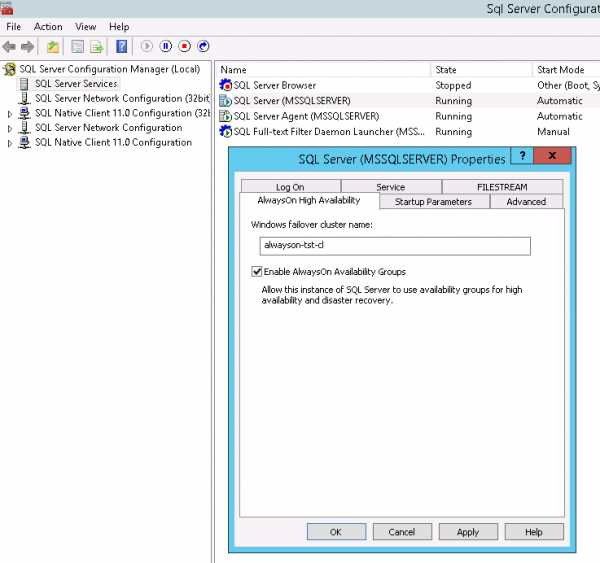
- Открываем SQL Server Management Studio, подключаемся к одному из наших SQL-серверов. В Object Exporer идем в папку AlwaysOn High Availability. Щелкаем правой кнопкой на Availability Groups и выбираем New Availability Group Wizard…. Запускается мастер создания группы доступности.
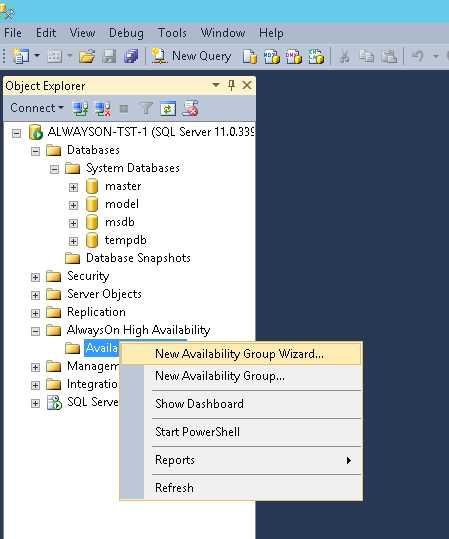
- На шаге Specify Availability Group Name указываем имя группы. Выбираем любое удобное для нас имя. Это исключительно имя объекта, ни на что в дальнейшем влиять не будет.
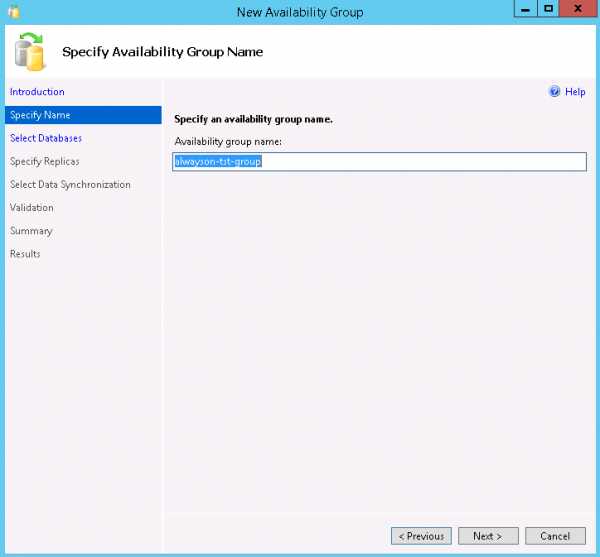
- На шаге Select Databases выбираем базу данных, которая будет добавлена в группу доступности.
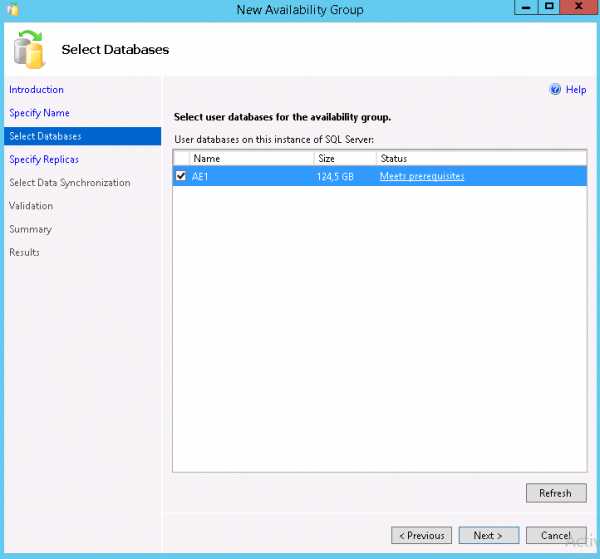
- На шаге Specify Replicas выполняем несколько действий. На вкладке Replicas добавляем второй SQL-сервер в конфигурацию. Automatic Failover - указываем по желанию (я в моем случае отключил). Synchronous Commit - лучше указать, т.к. именно это указывает на синхронный режим репликации, т.к. наиболее безопасный способ репликации с точки зрения защищенности данных от сбоя.
- Вторая необходимая вкладка на шаге Specify Replicas - это Listener. Тут мы создаем точку доступа к нашей группе доступности. Именно по этому адресу наши приложения будут получать доступ к базам данных из Availability Group.
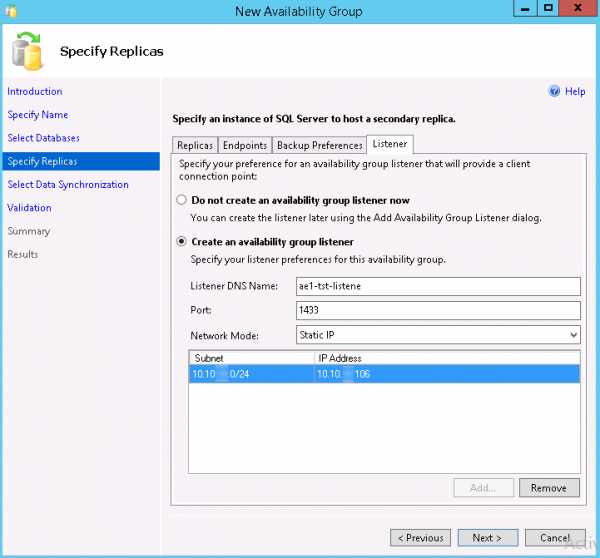
- На шаге Select Initial Data Synchronization указываем Full и указываем папку для первичной репликации базы данных между серверами. Доступ к сетевой папке должны иметь учетные записи, под которыми запущены и работают службы SQL-серверов.
- Дальнейшие шаги мастера New Availability Group не требуют вмешательства. В результате вы должны получить новую работающую группу AlwaysOn.
На этом будем считать нашу задачу выполненной. За вами - дальнейшие тесты по работоспособности вашего нового кластера.
b-blog.info
Установка и настройка Sphinx на Windows + MS SQL (Часть 1. Установка) · Dmitriy Azarov
Wed, Feb 5, 2014Установка
Поначалу пугала такая мощь как Sphinx. Учитывая, что материалов на русском языке достаточно мало - приходилось изучать документацию и различные сайты на английском. Тем не менее установка прошла очень гладко.
Сначала скачиваем файлы с сайта http://sphinxsearch.com/downloads/release/. Для работы с MS SQL достаточно первого файла. У меня это был Win64 binaries w/MySQL+id64 support. База представляет из себя zip архив. Распаковываем на диск.
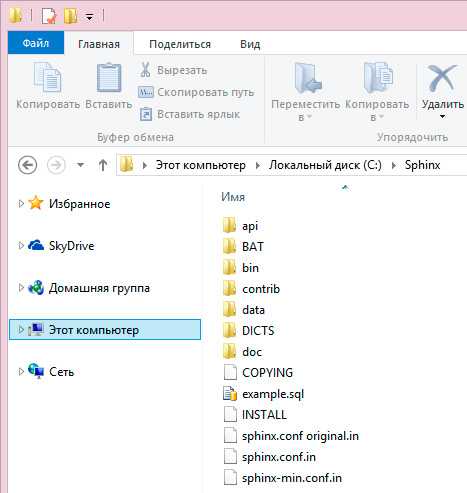
Я распаковал его по адресу C:\Sphinx. В файлах sphinx.conf.in и sphinx-min.conf.in есть примеры для конфигурации движка. Отличительная особенность от MS SQL - здесь все настройки задаются в файле конфигурации. Сам поиск это Windows служба. Отдельно поставляется модуль индексации - исполняемый файл, который пользуется тем же самым конфигурационным файлом. В файлах можно найти необходимые настройки. Большинство примеров в интернете реализовано для Unix/php. Мы же используем Windows + MS SQL.
До начала работы необходимо создать окружение. Сам сфинкс не будет ничего делать. Мы сами организуем файловую систему как считаем нужным. Создаем папку data, если ее нет и следующие папки внутри. Далее считаем что эти директории уже существуют.
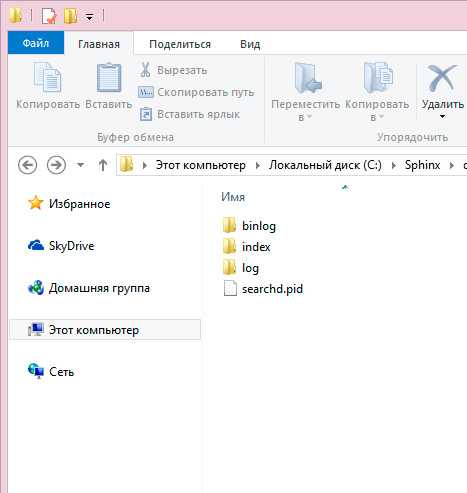
Установка службы Sphinx
Устанавливаем Sphinx как службу Windows. Но пока ее не запускаем, до написания конфигурационного файла.
Установка
c:\sphinx\bin\searchd –config c:\sphinx\sphinx.conf.in –install –servicename SphinxУдаление
c:\sphinx\bin\searchd –servicename Sphinx –deleteСледует заметить, что удаление службы необходимо при изменении расположения конфигурацинного файла. При любом измении содержимого конфигурационного файла необходимо перезапустить службу.
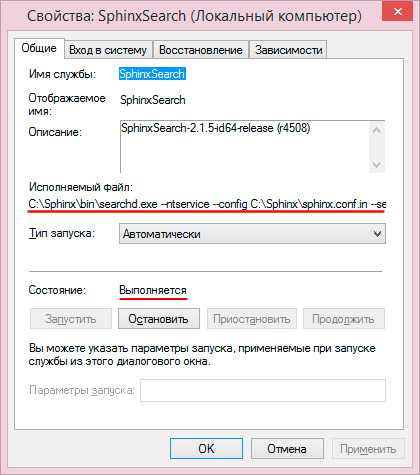
Настройка индексации
Все интересное как раз в этом файле - он рассказывает сфинксу как использовать наши данные. Какие поля какого типа, как искать и другие настройки. Файл состоит минимум из 4-х секций:
- Источник данных (source) - информация о сервере хранения данных, в моем случае SQL-Server
- Индекс (index) - настройки индексации данных, указанных в источнике
- Индексатор (indexer) - служба постройки индекса
- Поисковик (searchd) - Windows служба поиска.
Источник данных (source)
Источники могут наследовать настройки предков. Для начала создадим источник с информацией о сервере.
source mssql { type = mssql sql_host = \SQLSERVER sql_db = database_name sql_port = 1433 # optional, default is 3306, for ms sql is 1433 mssql_winauth = 1 mssql_unicode = 1}
Флаг mssql_winauth=1 говорит о том, что для соединения с сервером базы данных необходимо использовать Windows авторизацию. mssql_unicode - кодировка. Кодировки довольно тонкое место в Sphinx, т.к. о том, что кодировка не верная можно узнать только по результатам поиска. Сфинкс ничего не скажет о кодировке и проиндексирует данные в любой форме.
Следующий шаг - настройка данных для индексации
source catalog : mssql { sql_query = \ SELECT Id, Name, OfferPrice FROM SphinxView sql_attr_bigint = Id sql_field_string = Name sql_attr_float = OfferPrice}
sql_query - запрос для индексации данных. У нас это View в MS SQL Server. Ниже описываются атрибуты для индексации. Часто используемые типы:
- sql_attr_bigint - 64 бита, целое со знаком
- sql_attr_uint - 32 бита, целое без знака
- sql_attr_float - 32 бита, число с плавающей точкой
- sql_field_string - строка
Другие типы и дополнительная информация показаны в таблице ниже:
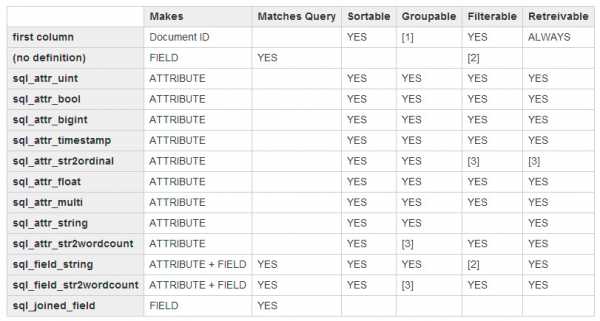
Секцию источника данных мы настроили, переходим дальше.
Настройка индекса (index)
index offers { source = catalog path = C:/Sphinx/data/index/offerscharset_type = utf-8 morphology = lemmatize_ru enable_star = 1 min_infix_len = 3}
По порядку:
- source = источник данных для индексирования
- path = путь к папке для индексирования. Причем offers - будет группа файлов
- charset_type = кодировка данных
- morphology = включаем всю мощь сфинкса, для полнотекстового поиска с учетом морфологии. Для лемматайзера необходимо дополнительно скачать словари http://sphinxsearch.com/downloads/dicts/
- enable_star = флаг, необходим для включения индексирования части слов
- min_infix_len = количество букв в слове для индексирования. Например для слова “test” с min_infix_len=2 в результат индексирования попадут вот эти значения: “te”, “es”, “st”, “tes”, “est” + само слово.
Индексатор (indexer)
indexer { mem_limit = 500M lemmatizer_base = C:\Sphinx\DICTS }Устанавливаем лимит памяти для программы индексирования. Нужно помнить, что индексирование - довольно важный процесс, но не должен отнимать много ресурсов на сервере. На локальной машине можно не жалеть. Вторым пунктом указываем путь до папки с файлом морфологии, который скачали в предыдущем пункте.
Поиск (searchd)
searchd { max_matches = 500000 listen = 9306:mysql41 pid_file = c:/sphinx/data/searchd.pid log = c:/sphinx/data/log/log.txt query_log = c:/sphinx/data/log/query_log.txt binlog_path = c:/sphinx/data/binlog/mysql_version_string = 5.0.0}Мы используем Sphinx для работы с MS SQL и используем ASP.NET API для доступа к данным. Поэтому необходимо настроить службу так, чтобы можно было удобно работать из .NET. В следующей статье расскажу, как работать со сфинксом из .net. А сейчас пока настроим.
- max_matches - ограничивает количество данных в работе. Это важно учесть при построении больших индексов и постраничной навигации. Эта настройка не ограничивает максимальное количество документов в базе, она работает в run-time. Это значит, что если max_matches=1000, то нельзя будет получить 30 документов, начиная с 1001.
- listen говорит о том, на каком локальном порте будет слушать сфинкс, а mysql41 - о том, что он будет эмулировать MySQL и можно будет к нему присоединиться используя MySQLConnector.
- mysql_version_string = 5.0.0 - Не все коннекторы работают хорошо, указываем, какой работает хорошо.
Запуск индексации
После всех настроек запускаем индексацию. Для этого был написан отдельный bat файл:
c:\sphinx\bin\indexer offers –config c:\sphinx\sphinx.conf.in –rotate –print-queriesФлаг –rotate означает, что индексаия будет выполняться наживую, т.е. при работающей службе поиска. После завершения индексации индекс будет заменен на новый.
И проиндексирована база данных
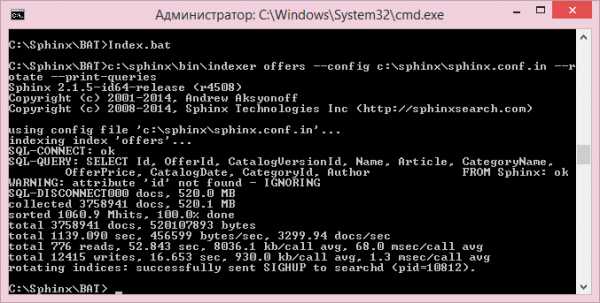
Результаты впечатляют
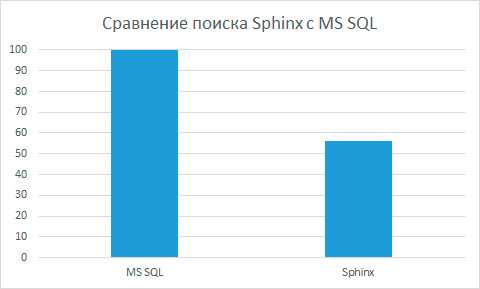
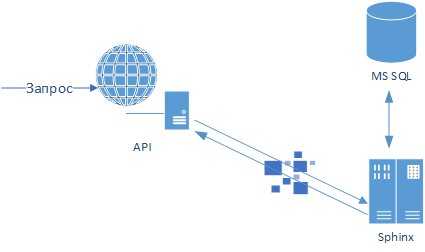
Общая схема API в разрабатываемом мобильном приложении выглядит так:
Ссылки
oxozle.com