Список всех столбцов индекса и индекса в SQL Server DB. Sql индексы
Индексы в SQL
1) Понятие индексаИндекс – это средство, обеспечивающее быстрый доступ к строкам таблицы на основе значений одного или нескольких столбцов.
Много разнообразия в этом операторе, ибо он не стандартизуется, поскольку стандарты не касаются вопросов производительности.
2) Создание индексовCREATE [UNUQUE] [CLUSTERED] INDEX ON ( [ASK|DESC])
3) Изменение и удаление индексовДля управления активностью индекса используется оператор:ALTER INDEX [ACTIVE|INACTIVE]Для удаления индекса используется оператор:DROP INDEX
Рекомендации по созданию индекса
a) Правила выбора таблиц1. Целесообразно индексировать таблицы, в которых выбирается не более 5% строк.2. Следует индексировать таблицы, не имеющие дублей в разделе WHERE оператора SELECT.3. Нецелесообразно индексировать часто обновляемые таблицы.4. Нецелесообразно индексировать таблицы, занимающие не более 2-х страниц (для Oracle это менее 300 строк), поскольку её полный просмотр не дольше.
b) Правила выбора столбцов1. Первичные и внешние ключи – часто используются для объединения таблиц, выборки данных и поиска. Это всегда уникальные индексы с максимальной полезностью2. При использовании опций ссылочной целостности всегда нужен индекс на FK.3. Столбцы, по которым часто производится сортировка и/или группирование данных.4. Столбцы, по которым часто производится поиск в разделе WHERE оператора SELECT.5. Не следует создавать индексов для длинных описательных столбцов.
c) Принципы создания составных индексов1. Составные индексы хороши, если столбцы по отдельности имеют мало уникальных значений, а составной индекс обеспечивает большую уникальность.2. Если все значения, выбираемые оператором SELECT, принадлежат составному индексу, то значения выбираются из индекса.3. Следует создавать составной индекс, если в разделе WHERE используется два или более значений объединенных оператором AND.
d) Не рекомендуется создаватьНе рекомендуется создавать индексы по столбцам, включая составные, которые:1. Редко используются для поиска, объединения и сортировки результатов запросов.2. Содержат часто меняющиеся значения, что требует частого обновления индекса замедляющего производительность БД.3. Содержат небольшое количество уникальных значений (менее 10% м/ж) или преобладающее число строк с одним-двумя значениями (город проживания поставщика Москва).4. К ним в разделе WHERE применяют функции или выражение, и индекс не работает.
e) Следует не забыватьСледует стремиться к уменьшению количества индексов, поскольку при большом их числе снижается скорость обновления данных. Так MS SQL Server рекомендует создавать не более 16 индексов на таблицу.Как правило, индексы создаются для запросов и поддержки ссылочной целостности.Если индекс не используется для запросов, то его следует удалять, а ссылочную целостность обеспечивать с использованием триггеров.
all4study.ru
sql-server - Список всех столбцов индекса и индекса в SQL Server DB
Ни один из вышеперечисленных не выполнил эту работу для меня, но это делает:
-- KDF9 concise index list for SQL Server 2005+ (see below for 2000) -- includes schemas and primary keys, in easy to read format -- with unique, clustered, and all ascending/descendings in a single column -- Needs simple manual add or delete to change maximum number of key columns -- but is easy to understand and modify, with no UDFs or complex logic -- SELECT schema_name(schema_id) as SchemaName, OBJECT_NAME(si.object_id) as TableName, si.name as IndexName, (CASE is_primary_key WHEN 1 THEN 'PK' ELSE '' END) as PK, (CASE is_unique WHEN 1 THEN '1' ELSE '0' END)+' '+ (CASE si.type WHEN 1 THEN 'C' WHEN 3 THEN 'X' ELSE 'B' END)+' '+ -- B=basic, C=Clustered, X=XML (CASE INDEXKEY_PROPERTY(si.object_id,index_id,1,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+ (CASE INDEXKEY_PROPERTY(si.object_id,index_id,2,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+ (CASE INDEXKEY_PROPERTY(si.object_id,index_id,3,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+ (CASE INDEXKEY_PROPERTY(si.object_id,index_id,4,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+ (CASE INDEXKEY_PROPERTY(si.object_id,index_id,5,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+ (CASE INDEXKEY_PROPERTY(si.object_id,index_id,6,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+ '' as 'Type', INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,1) as Key1, INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,2) as Key2, INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,3) as Key3, INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,4) as Key4, INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,5) as Key5, INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,6) as Key6 FROM sys.indexes as si LEFT JOIN sys.objects as so on so.object_id=si.object_id WHERE index_id>0 -- omit the default heap and OBJECTPROPERTY(si.object_id,'IsMsShipped')=0 -- omit system tables and not (schema_name(schema_id)='dbo' and OBJECT_NAME(si.object_id)='sysdiagrams') -- omit sysdiagrams ORDER BY SchemaName,TableName,IndexName ------------------------------------------------------------------- -- or to generate creation scripts put a simple wrapper around that SELECT SchemaName, TableName, IndexName, (CASE pk WHEN 'PK' THEN 'ALTER '+ 'TABLE '+SchemaName+'.'+TableName+' ADD CONSTRAINT '+IndexName+' PRIMARY KEY'+ (CASE substring(Type,3,1) WHEN 'C' THEN ' CLUSTERED' ELSE '' END) ELSE 'CREATE '+ (CASE substring(Type,1,1) WHEN '1' THEN 'UNIQUE ' ELSE '' END)+ (CASE substring(Type,3,1) WHEN 'C' THEN 'CLUSTERED ' ELSE '' END)+ 'INDEX '+IndexName+' ON '+SchemaName+'.'+TableName END)+ ' ('+ (CASE WHEN Key1 is null THEN '' ELSE Key1+(CASE substring(Type,4+1,1) WHEN 'D' THEN ' DESC' ELSE '' END) END)+ (CASE WHEN Key2 is null THEN '' ELSE ', '+Key2+(CASE substring(Type,4+2,1) WHEN 'D' THEN ' DESC' ELSE '' END) END)+ (CASE WHEN Key3 is null THEN '' ELSE ', '+Key3+(CASE substring(Type,4+3,1) WHEN 'D' THEN ' DESC' ELSE '' END) END)+ (CASE WHEN Key4 is null THEN '' ELSE ', '+Key4+(CASE substring(Type,4+4,1) WHEN 'D' THEN ' DESC' ELSE '' END) END)+ (CASE WHEN Key5 is null THEN '' ELSE ', '+Key5+(CASE substring(Type,4+5,1) WHEN 'D' THEN ' DESC' ELSE '' END) END)+ (CASE WHEN Key6 is null THEN '' ELSE ', '+Key6+(CASE substring(Type,4+6,1) WHEN 'D' THEN ' DESC' ELSE '' END) END)+ ')' as CreateIndex FROM ( ... ...listing SQL same as above minus the ORDER BY... ... ) as indexes ORDER BY SchemaName,TableName,IndexName ---------------------------------------------------------- -- For SQL Server 2000 the following should work -- change table names to sysindexes and sysobjects (no dots) -- change object_id => id, index_id => indid, -- change is_primary_key => (select count(constid) from sysconstraints as sc where sc.id=si.id and sc.status&15=1) -- change is_unique => INDEXPROPERTY(si.id,si.name,'IsUnique') -- change si.type => INDEXPROPERTY(si.id,si.name,'IsClustered') -- remove all references to schemas including schema name qualifiers, and the XML type -- add select where indid<255 and si.status&64=0 (to omit the text/image index and autostats)Когда последний столбец Key имеет все значения NULL, вы знаете, что их нет.
Фильтрация первичных ключей и т.д., как в исходном запросе, тривиальна.
ПРИМЕЧАНИЕ. Будьте осторожны с этим решением, поскольку оно не отличает индексированные и включенные столбцы.
qaru.site
database - Кластерные индексы SQL Server
Без кластеризованного индекса ваша таблица организована как куча. Это означает, что каждая строка, которая является вставкой, добавляется на странице данных в конце таблицы. Также, когда строки обновляются, они перемещаются на страницу данных в конце таблицы, если обновленные данные больше, чем раньше.
Если у вас нет кластеризованного индекса
Если у вас есть таблица, которая требует максимально быстрых вставок, но может пожертвовать обновлением и скоростью чтения, то для вас не будет работать кластерный индекс. Например, если бы у вас была таблица, которая использовалась в качестве очереди, например, множество вставок, которые позже просто считываются и перемещаются в другую таблицу.
Кластеризованные индексы
Кластерные индексы упорядочивают данные в вашей таблице на основе столбцов в кластерном индексе. Если вы скопируете неправильную вещь, например, uniqueidentifier, это может замедлить работу (см. Ниже).
Пока ваш кластеризованный индекс находится на значении, которое наиболее часто используется для поиска, и оно уникально и увеличивает их, вы получаете некоторые потрясающие преимущества производительности из кластерного индекса. Например, если у вас есть таблица под названием USERS, в которой вы обычно просматриваете пользовательские данные на основе USER_ID, тогда кластеризация на USER_ID ускорит работу всех этих поисков. Это просто уменьшает количество страниц данных, которые необходимо прочитать для получения ваших данных.
Если у вас слишком много ключей в вашем кластерном индексе, это также может замедлить работу.
Общие правила для кластеризованных индексов:
Не кластеры в каких-либо столбцах varchar.
Обычно кластеризация столбцов INT IDENTITY лучше всего.
Кластер на том, что вы обычно ищете.
Кластеризация на UniqueIdentifiers
С уникальными идентификаторами в индексе они крайне неэффективны, потому что нет естественного порядка сортировки. Основываясь на b-древовидной структуре индекса, вы получаете крайне фрагментированные индексы при использовании уникальных идентификаторов. После восстановления или реорганизации они все еще чрезвычайно фрагментированы. Таким образом, вы получаете более медленный индекс, который в конечном итоге становится действительно огромным в памяти и на диске из-за фрагментации. Также при вставках уникального идентификатора вы, скорее всего, получите разбивку страницы на индекс, что замедлит вашу вставку. Как правило, уникальные идентификаторы являются плохими новостями для индексов.
Резюме
Моя рекомендация заключается в том, что каждая таблица должна иметь кластерный индекс на нем, если не существует действительно веской причины не (например, таблица работает как очередь).
qaru.site
sql - Составные индексы MySQL и оператор BETWEEN
Ваш стиль очень необычный.
Большинство людей, вероятно, пишут WHERE began_at < NOW() AND finished_at > NOW()
Однако. Я бы рекомендовал поместить индекс в оба поля.
Комбинированный ключ не будет полезен вам, потому что вы только ускорите поиск для определенных комбинаций дат.
Ну, это не совсем так, потому что, если вы используете betree, комбинированный ключ поможет вам, но не так хорош, как если бы вы индексировали их отдельно. Комбинированные ключи очень хороши, если вы ищете комбинации полей с оператором равенства (=). Индексы полей SIngle лучше работают в запросах на генерацию.
Вы можете использовать Google для поиска "многомерного диапазона".
Причина в том, что все совпадающие поля в одном поле могут быть в основном найдены в log (n) времени в btrees. Таким образом, ваша общая продолжительность выполнения будет O (k * log (n)), которая равна O (log (n)).
Запросы многомерного диапазона имеют время выполнения O (sqrt (n)), которое выше. Однако есть и более эффективные реализации, которые также логарифмически исполняются во время работы. Однако они не полностью реализованы в mysql, поэтому это будет хуже или ужасно в зависимости от версии.
Итак, позвольте мне подвести итог:
-
Сравнения равенства по отдельным полям: хэш-индекс (время выполнения O (1))
-
Поиск диапазона по отдельным полям: индекс btree для отдельных полей (O (log (n)))
-
Поиск равенства по нескольким полям: комбинированный хэш-ключ (время выполнения O (1))
эти случаи ясны...
- Поиск диапазона по нескольким полям: отдельные индексы btree (O (log (n)))
вот где его не так ясно. с текущими версиями его явно лучше индексировать отдельно из-за причин, указанных выше. Благодаря идеальной реализации для этого варианта использования вы можете добиться более высокой производительности с помощью комбинированных клавиш, но нет системы, которая бы ее поддерживала. mysql поддерживает свободные индексы (которые вам нужны для этого) с версии 5.0, но только очень ограниченный, а оптимизатор запросов использует их в редких случаях afaik. не знаю о более новых версиях, например, 5.3 или что-то в этом роде.
однако с mysql, реализующим свободные индексы, объединенные ключи в полях, где вы выполняете запросы диапазона или сортировки в разных направлениях, становятся все более актуальными.
qaru.site
Кластерные и «обычные» индексы MySQL (InnoDB) / Хабрахабр
Все мы помним хрестоматийное объяснение «что такое индексы в БД и как они облегчают задачи поиска нужных строк». Уверен, у большинства из вас перед глазами встаёт нечто подобное: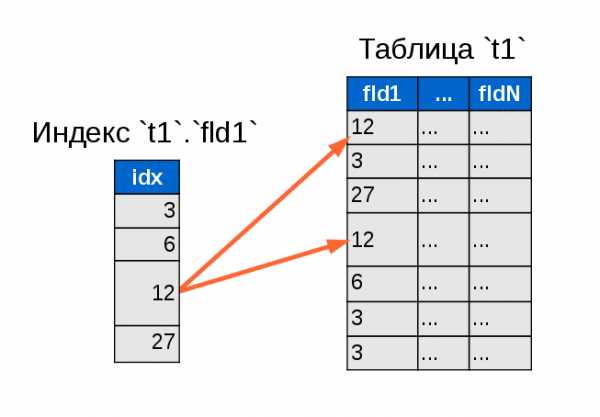
И сразу становится очевидно, насколько меньше данных нужно перелопатить для поиска двух-трёх нужных строк. Гениально. Просто. Понятно.
И лично мне всегда казалось, что улучшать эту схему некуда… Пока я не познакомился с кластерными индексами. Оказалось, что всё не так уж радужно с «обычными» индексами.
Итак, что же такое кластерный индекс, чем он лучше некластерного, и как с ним обстоит дело у MySQL.
Некластерные индексы
Чтобы не запутаться, до поры до времени будем рассматривать простой индекс по одному полю. Упрощённо некластерный индекс можно представить как отдельную таблицу, каждая строка в которой ссылается на одну или несколько строк в таблице с данными. Строки в индексной таблице упорядочены и сгруппированы по значениям ключевых полей. Представим элементарный запрос:
SELECT * FROM `t1` WHERE `fld1` = 12;Совсем без индексации будет прочитана и проверена каждая строка, и неудовлетворяющие условию строки просто не попадут в результат. Но прочитаны они будут.
При использовании «обычного», некластерного индекса, задача поиска сильно ускоряется. Во-первых, индексная таблица весит много меньше таблицы с данными, а значит элементарно может быть прочитана быстрее. Во-вторых, СУБД чаще всего стараются кешировать индексы в оперативную память, которая сама по себе много шустрее жёсткого диска*. В-третьих, в индексах отсутствуют дублирующиеся строки. А значит, как только мы нашли первое значение, поиск можно прекращать — оно же и последнее. В-четвёртых, данные в индексе отсортированы. А в-третьих и в-четвёртых вместе позволяют использовать алгоритм бинарного поиска (он же метод деления пополам), эффективность которого многократно превосходит простой перебор.
* Если ресурсы позволяют, таблицу данных тоже можно (и нужно) кешировать в оперативную память. Однако индексам и месту для них в оперативной памяти, по понятным причинам, принято уделять больше внимания.
Индексация — великая сила. Но если представить все указатели индексной таблицы на строки в таблице данных ОДНОВРЕМЕННО, получится достаточно сложная «паутина»:

И эта паутина, со множеством пересекающихся стрелок, подводит нас к проблеме (просто таки наглядно её демонстрирует), которую создаёт некластерный индекс.
Фрагментация
Оптимизатор MySQL может принять решение вообще не использовать индексы для поиска по небольшим таблицам (до пары десятков записей — зависит от конкретной структуры данных и индекса). Почему? Потому что поиск простым перебором читает данные последовательно. А указатель в индексе ссылается на разрозненные участки данных. И прыжки по ссылкам из индекса в конечном итоге могут стоить дороже полного перебора.
Итак, что мы имеем на данном этапе эволюции индексирования. Представьте большую, фрагментированную с точки зрения индексации, таблицу. Как данные приходили хаотичными и неотсортированными, так они и сохранялись. Теперь представьте индексную таблицу к ней. И наш старый добрый запрос:
SELECT * FROM `t1` WHERE `fld1` = 12;Что происходит? Находится значение в индексе — это быстро и просто — и из таблицы данных читаются строки, на которые этот индекс ссылается. Естественно, при большой фрагментированности таблицы накладные расходы на чтение из разных её частей становятся ощутимыми.
И вот тут-то нам и пригодятся…
Кластерные индексы
Кластерные индексы отличаются от некластерных точно так же, как оглавление книги отличается от алфавитного указателя. Алфавитный указатель (некластерный индекс) для точного слова (значения) даёт точные номера страниц (строки в БД). Оглавление же указывает диапазон страниц, соответствующих определённой главе, в которой уже найдётся искомое слово. Причём каждая глава, если она достаточно велика, может содержать собственное оглавление.
Кластерный индекс — это древовидная структура данных, при которой значения индекса хранятся вместе с данными, им соответствующими. И индексы, и данные при такой организации упорядочены. При добавлении новой строки в таблицу, она дописывается не в конец файла*, не в конец плоского списка, а в нужную ветку древовидной структуры, соответствующую ей по сортировке.
* В разных движках и при разных настройках это может быть вовсе и не конец, и вовсе и не файла. Слово файл здесь означает «некую единицу измерения данных, соответствующую одной таблице», а «конец файла» употребляется как символ последовательной, линейной записи.
Один из самых мощных и производительных движков для MySQL — InnoDB. Тому много причин, и одна из них — кластерные индексы. Проще всего понять как устроены кластерные индексы, если представить их в динамике: как они разрастаются по мере добавления данных, и как начинает ветвиться таблица.
Первый этап: плоский список
Данные в InnoDB хранятся страницами по 16 Кб. Размер одной страницы — это предельный размер узла нашей древовидной структуры, от которого зависит в какой момент начнётся ветвление. Если вся таблица помещается в одну страницу, то она хранится в виде плоского списка, отсортированного по ключевому полю, без отдельной индексной таблицы.

Точно такими же маленькими табличками в будущем будут представлены все наши данные, а соединять их в дерево будут цепочки индексных страниц.
Второй этап: дерево
Когда данные перестают помещаться в одну страницу, список превращается в дерево. Страница с данными разделяется на две, причём в том узле (на той странице), где раньше были данные, теперь располагается индекс, охватывающий обе новые страницы. Конкретный узел такого дерева обязан включать в себя индексы всех дочерних узлов или конечные данные, если узел последний. Узлы могут ссылаться друг на друга только в одном направлении: от родителя к потомку.

По мере добавления всё новых и новых данных, дерево будет усложняться и углубляться. И чем больше оно будет и ветвистее, тем больший выйгрышь даст такая схема хранения данны.
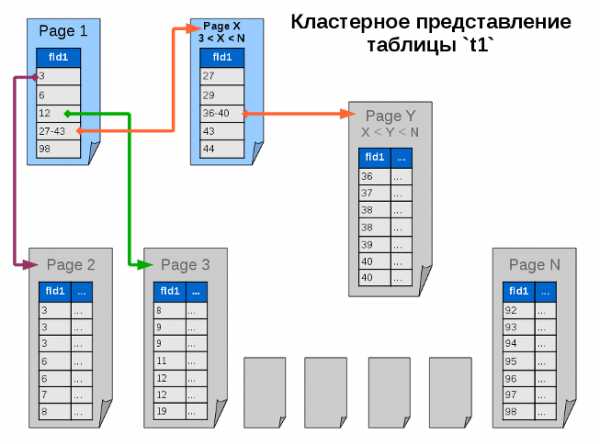
Серые страницы идентичны странице первого этапа — это просто отсортированные данные, листья (конечные узлы) нашего дерева. Голубые страницы — это промежуточные узлы дерева, содержащие только индекс и не содержащие данных. Стрелками помечены пути поиска определённых значений ключа.
Вспомним наш запрос (зелёная стрелка):
SELECT * FROM `t1` WHERE `fld1` = 12;Обращаясь к таблице, запрос попадает на первую страницу и получает индекс, тут же отправляющий его на конечную страницу с данными, где находятся строки, удовлетворяющие критериям поиска. Страница уже прочитана на этапе поиска, все данные собраны, БД может вернуть ответ.
Однако индекс, указывающий на другую страницу, не обязательно ведёт сразу на страницу с данными. Индекс может указывать на страницу с промежуточным индексом. Возможно, при больших объёмах таблицы, БД придётся провести больше итераций поиска, но каждая такая итерация включает минимальный объём данных, а потому в целом всё равно поиск проходит быстрее.
Здесь действует простое правило, актуальное для любого типа индекса: чем разнообразнее данные, тем эффективнее использовать индекс для поиска конкретных значений.
Поскольку данные являются частью индекса, отсортированы и целенаправленно фрагментированы, очевидно что для одной таблицы может использоваться только один кластерный ключ. Из такой, достаточно сложной логики хранения индексов и данных, есть ещё одно важное следствие: операции записи, а особенно изменение имеющихся данных ключевых полей — крайне ресурсоёмкий процесс. Старайтесь использовать для кластерных индексов редко изменяемые поля.
Что касается сложных (составных) кластерных ключей, для них действует абсолютно такая же схема, только сортировка данных осуществляется по двум полям. Сам же индекс мало отличается от некластерного составного ключа.
Кластерные ключи в InnoDB
Здесь всё просто. Каждая таблица InnoDB имеет кластерный ключ. Каждая. Без исключения.
Гораздо интереснее, какие поля для этого выбираются.
- Если в таблице задан PRIMARY KEY — это он
- Иначе, если в таблице есть UNIQUE (уникальные) индексы — это первый из них
- Иначе InnoDB самостоятельно создаёт скрытое поле с суррогатным ID размером в 6 байт
До третьего пункта лучше не доводить свой многострадальный сервер, и добавить таки ID самостоятельно.
И не забывайте, что InnoDB во вторичных ключах хранит полный набор значений полей кластерного ключа в качестве ссылки на конечную строку в таблице. Чем больше первичный ключ, тем больше вторичные ключи.
habr.com
использование индексов при настройке производительности
[Disclaimer: Данная статья была переведена в рамках "Конкурса на лучший перевод статьи" на сервисе Quizful. Ссылка на оригинал находится внизу страницы.]
Эффективное построение индексов - один из лучших способов повышения производительности приложения, работающего с базой данных. Без использования индексов, SQL сервер подобен читателю, пытающемуся найти слово в книге, просматривая каждую страницу. Если в книге есть предметный указатель (индекс), читатель может выполнить поиск необходимой информации гораздо быстрее.
В отсутствии индекса SQL сервер при получении данных из таблицы будет производить сканирование всей таблицы, и проверять каждую строку на предмет удовлетворению критерию запроса. Такое полное сканирование может оказаться катастрофическим для производительности всей системы, особенно если данных в таблицах много.
Одна из наиболее важных задач при работе с базой данных – это построение оптимального индекса, позволяющего повысить производительность системы. Большинство основных баз данных предоставляют инструменты для просмотра плана выполнения запроса и помогают настраивать и оптимизировать индексы. В этой статье выделено несколько хороших практических правил, которые применяются при создании или изменении индексов в базе данных. Для начала, рассмотрим ситуации, где индексирование улучшает производительность, а где индексирование может навредить.
Полезные индексы
Итак, индексирование таблиц будет полезно при поиске определенной записи в таблице с использованием инструкции Where. К таким запросам относятся, например, запросы поиска диапазона значений, запросы точного сопоставления определенному значению, запросы, осуществляющие слияние двух таблиц.
Например, запросы к базе данных Northwind, приведенные ниже, будут выполняться более эффективно при построении индекса по столбцу UnitPrice.
Delete from Products Where UnitPrice=1Select * from products Where UnitPrice between 14 AND 16Поскольку элементы индекса хранятся отсортированными, индексирование также оказывается полезным при построении запроса с использованием инструкции Order by. Без индекса записи загружаются и сортируются во время выполнения запроса. Индекс по UnitPrice позволит при обработке следующего запроса просто просканировать индекс и извлечь строки по ссылке. Если требуется упорядочить строки по убыванию, достаточно будет просто просканировать индекс в обратном порядке.
Select * From Products order by UnitPrice ASCГруппировка записи с использованием инструкции Group by также зачастую требует сортировки, таким образом, построение индекса по колонке UnitPrice будет полезным и при следующем запросе, подсчитывающим количество единиц продукта по каждой определенной цене
Select count(*), UnitPrice From Products Group by UnitPriceИндексы оказываются полезными для поддержания уникального значения столбца, так как СУБД может легко по индексу просмотреть содержится ли уже такое значение. По этой причине первичные ключи всегда проиндексированы.
Недостатки индексирования
Индексы ухудшают производительность системы во время изменений записи. В любое время при выполнении запроса на изменение данных в таблице индекс должен также изменяться. Для выбора оптимального количества индексов необходимо тестирование базы данных и наблюдение за ее производительностью. Статичные системы, где базы данных используются в основном для извлечения данных, например для построения отчетов, позволяют содержать большее количество индексов для поддержки запросов только на чтение. Базы данных с большим количеством транзакций для изменения данных будут нуждаться в небольшом количестве индексов для обеспечения более высокой пропускной способности.
Индексы занимают дополнительное место на диске и в оперативной памяти. Точный размер будет зависеть от количества записей в таблице, также как и от количества и размера столбцов в индексе. В большинстве случаев это не является основной проблемой, так как дисковым пространством сейчас легко пожертвовать для лучшей производительности.
Построение оптимального индекса
Есть целый ряд рекомендаций по построению наиболее эффективного индекса для приложения. Относительно столбцов, по которым будет построен индекс, существуют следующие правила.
Простой индекс
Простой индекс – это индекс, использующий значения одного поля таблицы. Использовать простой индекс выгодно по двум причинам. Во-первых, работа базы данных сильно нагружает жесткий диск. Большие индексные ключи будут заставлять базу данных выполнять большее количество операций ввода-вывода, что ограничивает производительность.
Во-вторых, поскольку элементы индекса часто вовлечены в сравнения, меньшие индексы легче сравнивать. По этим двум причинам единственная колонка целочисленного типа является лучшим индексом, так как он мал и легок для сравнения. Строки символов, с другой стороны, требуют посимвольного сравнения и внимания к обработке параметров.
Селективный индекс
Наиболее эффективные индексы – это индексы с малым процентом дублирующихся значений. К примеру, телефонный справочник города, в котором практически каждый имеет фамилию Смит, будет не столь полезен, если записи в нем отсортировать по фамилии.
Индекс с высоким процентом уникальных значений, также называют селективным индексом. Очевидно, уникальный индекс обладает наибольшей селективностью, так как не содержит дублирующихся значений. Многие СУБД могут отслеживать статистику о каждом индексе и могут распознавать, как много неповторяющихся значений содержит каждый индекс. Данная статистика используется при генерации плана выполнения запроса.
Покрывающие индексы
Индексы состоят из столбца данных, по которому собственно построен индекс и указателя на соответствующую строку. Это похоже на предметный указатель (индекс) книги: он содержит только ключевые слова и ссылку на страницу, на которую вы можете обратиться за дополнительной информацией. Обычно СУБД будет следовать указателям к строке из индекса, чтобы собрать всю информацию необходимую для запроса. Тем не менее, если индекс содержит все столбцы необходимые в запросе, информация может быть извлечена без обращения к самой таблице.
Рассмотрим индекс по столбцу UnitPrice, который уже упоминался выше. СУБД может использовать только элементы индекса для выполнения следующего запроса.
Select Count(*), UnitPrice From Products Group by UnitPriceТакой тип запроса называют покрывающим запросом, потому как все запрашиваемые столбцы могут быть извлечены из одного индекса. Для наиболее важных запросов вы можете рассмотреть возможность создания покрывающего индекса для возможно лучшей производительности. Такие индексы с большой вероятностью будут составными (использовано более чем один столбец), что противопоставляется первому принципу: создавать простые индексы. Очевидно, выбор оптимального количества столбцов в индексе возможно оценить только с помощью тестирования и наблюдения за производительностью базы данных в различных ситуациях.
Кластерный индекс
Многие базы данных имеют один специальный индекс к таблице, где все данные из строки содержаться в индексе. В SQL сервере такой индекс называется кластерным (кластеризованным). Кластерный индекс можно сравнить с телефонным справочником, потому как каждый элемент индекса содержит всю информацию, которая вам нужна и не содержит ссылок для получения дополнительных данных.
Есть общее правило - каждая нетривиальная таблица должна иметь кластерный индекс. Если возможно создать только один индекс к таблице, сделайте его кластерным. В SQL сервере при создании первичного ключа будет автоматически создан кластерный индекс (если он еще не содержится), используя столбец с первичным ключом, как ключ для индексирования. Кластерный индекс наиболее эффективный индекс (если он используется, то покрывает весь запрос) и во многих СУБД такой индекс способствует эффективному управлению пространством, запрашиваемым для хранения таблиц, так как в противном случае (без построения кластерного индекса) строки таблиц хранятся в неупорядоченной структуре, которую называют кучей.
При выборе столбцов для кластерного индекса будьте осторожны. Если вы изменить запись и поменяете значение столбца в кластерном индексе, база данных будет вынуждена перестроить элементы индекса (чтобы держать их в отсортированном порядке). Помните, элементы индекса для кластерного индекса содержать все значения столбцов, таким образом, изменение значение столбца сопоставимо с выполнением инструкции Delete и последующей за ней инструкцией Insert, что очевидно вызовет проблемы с производительностью, если делать это часто. По этой причине, кластерные индексы часто состоят из столбцов первичного ключа и внешнего ключа. Значения ключей если меняются, то очень редко.
Заключение
Определение правильных индексов, используемых в базе данных, требует тщательного анализа и тестирования системы. Практические методы, представленные в этой статье, являются хорошими правилами для построения индексов. После применения этих методов вам необходимо будет заново протестировать ваше конкретное приложение при ваших конкретных аппаратных условиях, памяти и операциях.
----------Оригинальный текст статьи: SQL Performance Tuning using Indexes
www.quizful.net
Выбор и использование индексов MySQL
Первичный индекс
При построении первичного индекса необходимо учитывать несколько факторов:
INT + AUTO_INCREMENT - лучший выбор
использовать строки - плохо, много места и долгая обработка
MyISAM пакует индексы - еще медленнее для строк (до 6 раз)
InnoDB включает первичный индекс во вторичные - дополнительное место
в InnoDB первичный ключ - кластерный индекс по умолчанию
Случайные строки (MD5, SHA1) - медленные выборки и вставка (соседние записи не являются соседними в индексе)
Хранение UUID - удалить тире, еще лучше преобразовать в BINARY(16) с помощью UNHEX()
Виды индексов
Поиск элемента в хорошей хэш-таблице занимает О(1).
В хорошо сбалансированном дереве — O(log(n)).
В массиве — O(n).
Наилучшие алгоритмы сортировки имеют сложность O(n*log(n)).
Плохие алгоритмы сортировки — O(n2).
https://habrahabr.ru/company/mailru/blog/266811/
B-TREE
Возможности
B-TREE - основной используемый типа индекса. Поиск может выполняться:
по полному значению
по левостороннему префиксу, по первой колонке индекса
по интервалу значений (range), только для первой колонки
по фиксированному значению первой колонки (или нескольких) и интервалу на последующую
Также эти индексы используются при сортировке, а также работаю как покрывающие индексы (то есть из них можно получиться значение, не обращаясь к таблице).
Ограничения
Для B-TREE индексов существуют и ограничения:
нельзя искать по суффиксу (имена, оканчивающиеся на определенную букву)
нельзя пропустить колонку в индексе
не учитываются колонки справа от сравнения с интервалом (date_of_birth):
IN (v1,v2,v3) тоже считается интервалом (range), но после него учитываются.
HASH
Особенности
Основное преимущество - очень быстрый поиск по полному значению индекса, но масса ограничений:
нельзя использовать для покрывающих индексов
нельзя использовать для поиска по префиксу
нельзя использовать для сортировки
не может использовать в выражениях <, >, только в =, IN, <>
не эффективен при частых коллизиях
Эмуляция через B-TREE
Предположим, у нас есть большой и медленный индекс по url:
SELECT id FROM url WHERE url="http://www.mysql.com";Можно построить быстрый индекс по url_crc, индекса по url нет:
SELECT id FROM url WHERE url='http://www.mysql.com' AND url_crc=CRC32('http://www.mysql.com');Выборка ведется по url для разрешения коллизий.
Заполнение url_crc - триггер или слой модели. Внимательно выбираем хэш-функцию, SHA1, MD5 - слишком сложные и длинные.
crc32-trigger.sql DELIMITER $$ CREATE TRIGGER `url_crc_fill` BEFORE INSERT ON `url` FOR EACH ROW BEGIN SET NEW.url_crc = CRC32(NEW.url); END $$ DELIMITER ;Еще один пример для точного поиска по адресу:
DROP TRIGGET IF EXISTS `address_crc_fill_insert`; DROP TRIGGET IF EXISTS `address_crc_fill_update`; DELIMITER $$ CREATE TRIGGER `address_crc_fill_insert` BEFORE INSERT ON `MarketNavigator` FOR EACH ROW BEGIN SET NEW.FullAddressCRC = CRC32(NEW.FullAddress); END $$ CREATE TRIGGER `address_crc_fill_update` BEFORE UPDATE ON `MarketNavigator` FOR EACH ROW BEGIN IF NEW.FullAddress <> OLD.FullAddress THEN SET NEW.FullAddressCRC = CRC32(NEW.FullAddress); END IF; END $$ DELIMITER ;Использование индексов
Принцип изолирования колонок
Индекс не используется, если колонка внутри выражения или вызова функции:
SELECT actor_id FROM actor WHERE actor_id + 1 = 5; SELECT ... WHERE TO_DAYS(CURRENT_DATE) * TO_DAYS(date_col) <= 10;Часто можно переписать запрос с учетом принципа изолирования колонок, тогда индексы используются:
SELECT actor_id FROM actor WHERE actor_id = 4; SELECT ... WHERE date_col >= DATE_SUB(CURRENT_DATE, INTERVAL 10 DAY);Префиксные индексы и селективность
Для длинных строк часто имеет смысл строить индекс по префиксу строки (а не по полному значению), уменьшая место и ускоряя обработку.
При этом важно не забывать о селективности:
selectivity = cardinality / общее количество значений cardinality - количество различных значенийДлина префикса - компромисс между хорошей селективностью и занимаемым местом.
По реальным данным считаем селективность для различных длин префиксов, выбираем оптимальную.
Кластеризованный индекс
Определяет физический порядок записей. В случае InnoDB это единая структура для хранения и индекса, и данных. В качестве кластеризованного индекса выбираются:
1. первичный ключ 2. первый уникальный ключ, если нет первичного 3. суррогатный первичный ключ в порядке добавления записей, если нет уникальных ключей
Все прочие созданные индексы ссылаются не на записи, а на значения кластеризованного индекса, это важная особенность InnoDB.
Преимущества
очень быстрая выборка по первичному ключу
эффективный поиск по интервалу первичного ключа
быстрая сортировка по первичному ключу
покрывающие индексы автоматически используют первичный ключ
быстрая вставка в порядке сортировки первичного ключа
Недостатки
вторичные индексы занимают больше места
при поиске по вторичному ключу выполняется дополнительный просмотр по первичному
при обновлении первичного ключа - перемещение строки
медленная вставка, если порядок не совпадает с сортировкой первичного ключа
Как правило, достоинства перевешивают недостатки.
Покрывающие (covering) индексы
MySQL может брать данные из индекса, не обращаясь к записи, в результате получаем значительное увеличение производительности:
меньше обрабатываемых данных
быстрее навигация по записям
лучшее кеширование
для InnoDB - нет дополнительного поиска по первичному ключу
Существуют ограничения:
работает только для B-TREE индексов
все запрашиваемые колонки должны быть в индексе
условие LIKE - только по префиксу (pattern%)
Например, в приведенном ниже запросе покрывающий индекс не используется: поле price не в индексе, LIKE не по префиксу:
SELECT store_id, film_id, price FROM store_film WHERE store_id = 1 AND name LIKE '%mission%';Дублирующиеся и избыточные индексы
Дублирующиеся (dublicate) индексы - индексы по одним и тем же колонкам в том же порядке, всегда нужно оставлять только один.
Избыточные (redundant) индексы - если один индекс содержит другой: (A,B) и (A,B,C).
Прежде чем добавить новый индекс - смотрим, нельзя ли расширить старый, но возможны варианты:
(A INT, B INT) и (A INT, B INT, C VARCHAR)Второй индекс может быть существенно медленнее первого, в том числе для покрывающих индексов.
Многокритериальные индексы
Если необходим поиск по форме, содержащей много полей:
CREATE INDEX search ON people(gender,eye_color,hair_color,city,age);Работает с запросами gender, gender+country, gender+country+region. Но что делать с поиском по region+age?
Можно построить еще один индекс, однако большое количество индексов (по одному на каждую комбинацию) - плохо.
Иногда можно извернуться, указав отсутствующее в запросе поле со всеми возможными значениями
... WHERE eye_color IN('brown','blue','hazel') AND hair_color IN('black','red','blonde','brown') AND gender IN('M','F');Сортировка по индексам
Для того, чтобы индексы использовались при сортировке, необходимо выполнение следующих требований:
порядок колонок в индексе должен точно совпадать с ORDER BY
не работает для разнонаправленной сортировки (ASC/DESC) при нескольких колонках в ORDER BY
для JOIN - если ORDER BY содержит только колонки первой таблицы
левосторонняя префиксность, кроме случаев ограничения в WHERE по константе
Пример:
CREATE INDEX rental_date (rental_date,inventory_id,customer_id); SELECT rental_id, staff_id FROM rental WHERE rental_date = '2005-05-25' ORDER BY inventory_id, customer_id;Сортировка по индексу не работает в следующих случаях:
... WHERE rental_date = '2005-05-25' ORDER BY inventory_id, staff_id; ... WHERE rental_date = '2005-05-25' ORDER BY inventory_id DESC, customer_id ASC; ... WHERE rental_date = '2005-05-25' ORDER BY customer_id; ... WHERE rental_date > '2005-05-25' ORDER BY inventory_id, customer_id; AND hair_color IN('black','red','blonde','brown') AND gender IN('M','F');Порядок следования полей в индексе
При построении индекса в большинстве случаев можно придерживаться следующего принципа:
сначала колонки, по которым делается выборка по значению, в порядке убывания селективности
потом колонка, по которой делается выборка по интервалу
В тексте WHERE порядок следования условий как правило не играет роли, оптимизатор запросов достаточно умный.
В SORT - еще как влияет, поэтому нужно еще и учитывать наиболее частые сортировки.
pushorigin.ru