Группировка результатов SQL от Союза. Sql группировка
Как осуществляется группировка SQL: синтаксис условия group by
От автора: группировка SQL — условие GROUP BY — используется вместе с оператором SELECT для организации идентичных данных в группы. Это условие указывается в инструкции SELECT после условия WHERE и перед условием ORDER BY.
Синтаксис
Основной синтаксис условия GROUP BY приведен в следующем блоке кода. Условие GROUP BY должно указываться после условия WHERE и перед условием ORDER BY, если оно используется.
SELECT столбец1, столбец2 FROM имя_таблицы WHERE [условие] GROUP BY столбец1, столбец2 ORDER BY столбец1, столбец2
SELECT столбец1, столбец2 FROM имя_таблицы WHERE [условие] GROUP BY столбец1, столбец2 ORDER BY столбец1, столбец2 |
Пример
Давайте рассмотрим таблицу CUSTOMERS которая содержит следующие записи:
Бесплатный курс по PHP программированию
Освойте курс и создайте динамичный сайт на PHP и MySQL с полного нуля, используя модель MVC
В курсе 39 уроков | 15 часов видео | исходники для каждого урока
Получить курс сейчас!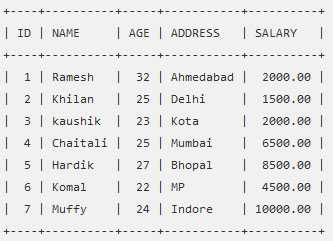
Если вы хотите узнать сумму зарплаты для каждого клиента, тогда запрос GROUP BY должен быть следующим.
SELECT NAME, SUM(SALARY) FROM CUSTOMERS GROUP BY NAME;
SELECT NAME, SUM(SALARY) FROM CUSTOMERS GROUP BY NAME; |
Этот код дает следующий результат:
Теперь давайте рассмотрим другой пример, в котором таблица CUSTOMERS содержит следующие записи с дублирующимися именами:
Теперь, если вы хотите узнать сумму зарплаты для каждого клиента, тогда запрос GROUP BY должен быть следующим:
SELECT NAME, SUM(SALARY) FROM CUSTOMERS GROUP BY NAME;
SELECT NAME, SUM(SALARY) FROM CUSTOMERS GROUP BY NAME; |
Этот код дает следующий результат -
Источник: https://www.tutorialspoint.com/
Редакция: Команда webformyself.
Бесплатный курс по PHP программированию
Освойте курс и создайте динамичный сайт на PHP и MySQL с полного нуля, используя модель MVC
В курсе 39 уроков | 15 часов видео | исходники для каждого урока
Получить курс сейчас!Хотите изучить MySQL?
Прямо сейчас посмотрите 24-х часовой курс по базе данных MySQL!
Смотреть курсwebformyself.com
предложения GROUP BY, HAVING и агрегатные функции
Предложение GROUP BY (инструкции SELECT) позволяет группировать данные (строки) по значению какого-либо столбца или нескольких столбцов или выражений. Результатом будет набор сводных строк.
Каждый столбец в списке выборки должен присутствовать в предложении GROUP BY, исключение составляют только константы и столбцы — операнды агрегатных функций.
Таблицу можно сгруппировать по любой комбинации ее столбцов.
Агрегатные функции используются для получения из группы строк одного единственного суммарного значения. Все агрегатные функции выполняют вычисления над одним аргументом, который может быть или столбцом, или выражением. Результатом вычислений любой агрегатной функции является константное значение, отображаемое в отдельном столбце результата.
Агрегатные функции указываются в списке столбцов инструкции SELECT, которая также может содержать предложение GROUP BY. Если в инструкции SELECT отсутствует предложение GROUP BY, а список столбцов выборки содержит, по крайней мере, одну агрегатную функцию, тогда он не должен содержать простых столбцов. С другой стороны, список выборки столбцов может содержать имена столбцов, которые не являются аргументами агрегатной функции, если эти столбцы служат аргументами предложения GROUP BY.
Если запрос содержит предложение WHERE, то агрегатные функции вычисляют значение для результатов выборки.
Агрегатные функции MIN и MAX вычисляют наименьшее и наибольшее значение столбца соответственно. Аргументами могут быть числа, строки и даты. Все значения NULL удаляются перед вычислением (т.е. в расчет не берутся).
Агрегатная функция SUM вычисляет общую сумму значений столбца. Аргументами могут быть только числа. Использование параметра DISTINCT устраняет все повторяющиеся значения в столбце перед применением функции SUM. Аналогично удаляются все значения NULL перед применением этой агрегатной функции.
Агрегатная функция AVG возвращает среднее значение для всех значений столбца. Аргументами также могут быть только числа, а все значения NULL удаляются перед вычислением.
Агрегатная функция COUNT имеет две разные формы:
- COUNT([DISTINCT] col_name) — подсчитывает количество значений в столбце col_name, значения NULL не учитываются
- COUNT(*) — подсчитывает количество строк в таблице, значения NULL также учитываются
Если в запросе используется ключевое слово DISTINCT, перед применением функции COUNT удаляются все повторяющиеся значения столбца.
Функция COUNT_BIG аналогична функции COUNT. Единственное различие между ними заключается в типе возвращаемого ими результата: функция COUNT_BIG всегда возвращает значения типа BIGINT, тогда как функция COUNT возвращает значения данных типа INTEGER.
В предложении HAVING определяется условие, которое применяется к группе строк. Оно имеет такой же смысл для групп строк, что и предложение WHERE для содержимого соответствующей таблицы (WHERE применяется до группировки, HAVING после):
Параметр condition содержит агрегатные функции или константы.
51. Язык sql. Группировка данных.
Группировка данных: GROUP BY – выполняет группировку строк таблицы по определенным критериям. GROUP BY [ALL] <условие группировки> [,…,n] ORDER BY – предназначен для упорядочения набора данных, возвращаемого после выполнения запроса. SELECT TOP 10 * FROM Дисциплины
27.Текстовые процессоры. Назначение, функциональные возможности
Текстовый процессор — вид прикладной компьютерной программы, предназначенной для производства (включая набор, редактирование, форматирование, иногда печать) любого вида печатной информации. Иногда текстовый процессор называют текстовым редактором второго рода.
Текстовыми процессорами в 1970-е — 1980-е годы называли предназначенные для набора и печати текстов машины индивидуального и офисного использования, состоящие из клавиатуры, встроенного компьютера для простейшего редактирования текста, а также электрического печатного устройства. Позднее наименование «текстовый процессор» стало использоваться для компьютерных программ, предназначенных для аналогичного использования.
Текстовые процессоры, в отличие от текстовых редакторов, имеют больше возможностей для форматирования текста, внедрения в него графики, формул, таблиц и других объектов. Поэтому они могут быть использованы не только для набора текстов, но и для создания различного рода документов, в том числе официальных. Наиболее известным примером текстового процессора является Microsoft Word.
45.Ограничения целостности бд. Виды ограничений целостности
Ограничение целостности устанавливает правила на уровне БД, определяя набор проверок для таблиц системы. Эти проверки автоматически выполняются всякий раз, когда вызывается оператор вставки, модификации или удаления данных в таблице. Если какие либо ограничения нарушены, операторы отменяются. Поскольку ограничения условности проверяются на уровне БД, они выполняются независимо от того, откуда были инициированы операторы вставки, модификации или удаления. Для таблиц можно задавать следующие типы ограничений целостности:
NOT NULL. Это ограничение устанавливается для столбца, чтобы указать, что столбец должен иметь значение в каждой строке, т.е. некоторое непустое значение.
PRIMARY KEY (первичный ключ) . Ограничение определяет столбец или группу столбцов, которую можно использовать для уникальной идентификации строки. Никакие две строки в таблице не могут иметь одинаковые значения столбцов первичного ключа. Кроме того, столбцы первичного ключа должны всегда содержать значение. Все эти условия гарантируют то, что в нашем распоряжение будет одна и только одна строка, соответствующая критериям связывания. Первичные ключи могут быть или именованные (пользователем) или неименованные ( Oracle составляет имя сам). В первичных ключах не могут использоваться столбцы типа: raw, long, long raw.
UNIQUE (уникальный). Ограничение UNIQUE используется для определения того, что значения в столбце не должно повторяться в другой строке этой таблицы, определяет вторичный ключ для таблицы. Это столбец или группа столбцов, которые можно использовать как уникальную идентификацию строки. Никакие две строки не могут иметь одинаковые значения для столбца или столбцов ключа UNIQUE. Столбцы для ограничения UNIQUE не обязательно NOT NULL. Можно сформировать ограничение таблицы, указав, что в таблице не должна повторяться комбинация столбцов. К примеру: можно в начале объявить стандартно emp_id number(5), person_id date а под конце объявить что: unique( emp_id, person_id) – и получиться, что сочетание значений этих полей, должно быть уникальным в каждой строке.
FOREIGN KEY (внешний ключ). FOREIGN KEY, устанавливает отношение целостности между таблицами. Оно требует, чтобы столбец или набор столбцов в одной таблице совпадал с первичным или вторичным ключом другой таблицы. С момента создания внешнего ключа ссылающегося на первичный ключ некой таблицы удаление таблицы будет – запрещено. И обойти это ограничение можно только удалив ограничение. Внешние ключи могут быть именованные или неименованные.
CHECK. Ограничение CHECK определяет логику проверки, которая должна жать результат true (истина) для оператора вставки, модификации или удаления из таблицы. Ограничение CHECK гарантирует, что значение в измененной строке удовлетворяют заданному набору проверок правильности.
ИНДЕКСЫ (INDEX). Ограничения PRIMARY KEY и UNIQUE автоматически создают индексы на столбцах, для которых они определены, если ограничение активизируется при создании. Если индекс уже существует на столбцах, которые составляют ограничение PRIMARY KEY и UNIQUE, то использует именно этот индекс и Oracle не может создать новый.
TRRIGERS (Триггеры) – с программный элемент хранимый в БД выполняемый автоматически, в определенных ситуациях, не имеющий входных или выходных параметров, что в конечном итоги и является причиной невозможности вызвать его явно, непосредственно, его вызывает только сама база данных Oracle. Выходные данные триггера должны быть также применимы к БД, а не возвращены вызывающей программе или отображены на экране.
48.Язык SQL. Извлечение данных Основным инструментом выборки данных в языке SQL является команда SELECT. С помощью этой команды можно получить доступ к данным, представленным как совокупность таблиц практически любой сложности. Чаще всего используется упрощенный вариант команды SELECT, имеющий следующий синтаксис: SELECT <Список_выбора> [INTO <Новая_таблица>] FROM <Исходная_таблица> [WHERE <Условие_отбора>] [GROUP BY <Ключи_группировки>] [HAVING <Условие_отбора>] [ORDER BY <Ключи_сортировки> [ASC | DESC] ] Инструкция SELECT разбивается на отдельные разделы, каждый из которых имеет свое назначение. Обязательными являются только разделы SELECT и FROM, а остальные разделы могут быть опущены. Полный список разделов следующий: SELECT UNION INTO ORDER BY FROM COMPUTE WHERE FOR GROUP BY OPTION HAVING Основное назначение радела SELECT – задание набора столбцов, возвращаемых после выполнения запроса, т.е. внешнего вида результата. В простейшем случае возвращается столбец одной из таблиц, участвующих в запросе. В более сложных ситуациях набор значений в столбце формируется как результат вычисления выражения. Такие столбцы называются вычисляемыми, и по умолчанию им не присваивается никакого имени.
studfiles.net
Понятие группировки в Transact SQL
Группировка в Transact SQL сложна тем, что из исходной таблицы она делает новую таблицу. На вход поступает исходная таблица. Операции группировки группируют ее объекты по какому-то принципу, и на выходе получаем список групп.
Пример: есть готовая БД с книгами разных тематик (type). Сгруппируем их по типу:
SELECT Type FROM titles GROUP BY TypeПри этом можно группировать, используя агрегатные функции: Count, Min, Max, Avg:
SELECT Type, Count(*), AVG(price), Min(price), Max(price) FROM titles GROUP BY TypeДругой пример: есть БД интернет-магазина, в которой колонка дата заказа (order_date). Узнаем, сколько было заказов по годам:
SELECT Year(order_date), Count(*) FROM orders GROUP BY Year(order_date)Теперь узнаем год, в котором наибольшее число заказов:
SELECT TOP(1) Year(order_date) FROM orders GROUP BY Year(order_date) ORDER BY Count(*) DESCДругой пример: есть БД с книгами разных категорий. Узнаем, в какой категории самая дорогая книга:
SELECT TOP(1) FROM titles GROUP BY Type ORDER BY Max(price) DESC -- можно без группировки SELECT TOP(1) Type FROM titles ORDER BY price DESCГруппировать можно по нескольким полям:
SELECT price, title FROM titles GROUP BY price, titleФильтрация сгруппированных таблиц
Для группировки выборки в исходной таблице используется конструкция WHERE. Но в новой таблице после группировки это не работает. Вместо WHERE применяют оператор HAVING:
SELECT Type, Count(*) FROM titles GROUP BY Type HAVING Count(*)>1В идеале фильтрацию лучше делать до группировки — в исходной таблице, т.е. попытаться отбросить побольше лишнего. А применение HAVING, т.е. фильтрация после группировки, тормозит запросы.
Вывод: суть работы группировок несложен. Берется исходная таблица. Отфильтровываем нужные данные из нее. Далее группироем эти данные в новую таблицу. И работаем уже с новой таблицей, к ней применяем функции агрегации и группировки (HAVING).
1st-network.ru
33. ГРУППИРОВКА ДАННЫХ В ЯЗЫКЕ SQL
Главная » Информационные системы » Управление данными » 33. ГРУППИРОВКА ДАННЫХ В ЯЗЫКЕ SQLГрупировка данных.
Группировка данных в операторе SELECT осуществляется с помощью ключевого слова GROUP BY и ключевого слова HAVING, с помощью которого задаются условия разбиения записей на группы.GROUP BY неразрывно связано с агрегирующими функциями, без них оно практически не используется. GROUP BY разделяет таблицу на группы, а агрегирующая функция вычисляет для каждой из них итоговое значение. Определим для примера количество книг каждего издательства в нашей базе данных:
SELECT publishers.publisher, count(titles.title)FROM titles,publishersWHERE titles.pub_id=publishers.pub_idGROUP BY publisher; Kлючевое слово HAVING работает следующим образом: сначала GROUP BY разбивает строки на группы, затем на полученные наборы накладываются условия HAVING. Например, устраним из предыдущего запроса те издательства, которые имеют только одну книгу: SELECT publishers.publisher, count(titles.title)FROM titles,publishersWHERE titles.pub_id=publishers.pub_idGROUP BY publisherHAVING COUNT(*)>1; Другой вариант использования HAVING - включить в результат только те издательтва, название которых оканчивается на подстроку Press: SELECT publishers.publisher, count(titles.title)FROM titles,publishersWHERE titles.pub_id=publishers.pub_idGROUP BY publisherHAVING publisher LIKE '%Press'; В чем различие между двумя этими вариантами использования HAVING? Во втором варианте условие отбора записей мы могли поместить в раздел ключевого слова WHERE, в первом же варианте этого сделать не удасться, поскольку WHERE не допускает использования агрегирующих функций.Друзья! Приглашаем вас к обсуждению. Если у вас есть своё мнение, напишите нам в комментарии.
it-iatu.ru
sql - Группировка результатов SQL от Союза
Эй, ребята, у меня есть таблица в моей базе данных, используемая для того, чтобы пользователи могли следовать друг за другом.
Таблица выглядит следующим образом: Уникальный идентификатор FollowerID FollowedUserID
FollowID - это идентификатор пользователя, который следит за кем-то еще
FollowedUserID - это идентификатор пользователя, за которым следит пользователь FollowID
Я хотел бы получить список соединений из этой таблицы, основанный на одном пользователе. Мой запрос должен возвращать все другие идентификаторы пользователя, которые текущий пользователь выполняет или сопровождает без перекрытий.
Итак, у нас есть несколько записей здесь:
FollowerID FollowedUserID 1 2 1 3 4 1 2 1Это показало бы, что пользователь 1 следит за пользователями 2 и 3, а за пользователями 2 и 3 следует пользователь 1. С другой стороны спектра он показывает, что пользователю 1 следуют пользователи 2 и 3.
То, что я хотел бы сделать, это выяснить соединения, которые пользователь 1 имеет, поэтому запрос должен возвращать пользователей: 2, 3 и 4 (пользователь 1 следуют пользователям 2 и 3 и за ними следует пользователь 4)
Как я могу достичь этого из одного запроса?
A соединение считается либо выполняемым, либо следующим за кем-то другим, поэтому возможно, что могут произойти некоторые повторяющиеся результаты (если оба пользователя следуют друг за другом). Я хотел бы иметь возможность группировать эти результаты, чтобы результат отличался.
Я пробовал запрос UNION, похожий на:
SELECT FollowerID, FollowedUserID From Follows WHERE FollowerID = 1 UNION SELECT FollowerID, FollowedUserID FROM Follows WHERE FollowedUserID = 1Теоретически я хотел бы Группировать FollowerID и FollowedUserID вместе, чтобы они отличались.
Мне не интересно получить нечеткий результат, а затем создать набор уникальных результатов php side - запрос должен возвращать только отдельные значения.
qaru.site
Группировка данных по непрерывным периодам T-SQL
В процессе поиска интересной вакансии наткнулся на занятное тестовое задание, в оригинале оно звучит так.
Есть таблица, отражающая изменения параметров по времени. Если упрощенно, то там есть 4 поля:idProperty (FK) — что продаютagent (FK) — кто предлагаетprice — почемsince — с каких пор
Например, если кто-то поставил цену 1000, потом снизил до 900, а потом вообще убрал свое предложение, то это выглядит так:
| 1 | 1000 | 1 апреля |
| 1 | 900 | 2 апреля |
| 1 | NULL | 3 апреля |
Агентов может быть много, и они могут по много раз менять свои предложения. Нужно выяснить периоды, в течение которых были предложения хоть от кого-то. Т.е. из этого:
| 1 | 1000 | 1 мая |
| 1 | 900 | 5 мая |
| 1 | NULL | 10 мая |
| 1 | 1100 | 20 мая |
| 1 | NULL | 25 мая |
| 2 | 1200 | 3 мая |
| 2 | 1300 | 12 мая |
| 2 | NULL | 15 мая |
нужно получить такое:
| 1 мая | 15 мая | 900 |
| 20 мая | 25 мая | 1100 |
потому что между 15 и 20 мая предложений не было, а потом они снова появились.
На каком-нибудь императивном языке сделать это проще простого, нужно только пройти в цикле по данным и подсчитывать записи. А вот как на SQL?
Пробовал поискать, но «группировка» — слишком общий термин, а лучше я не придумал.
Наверное, можно для каждой даты проверять, правда ли, что для всех агентов их последнее предложение перед этой датой — NULL, а потом искать первое не-NULL предложение после этой даты, а потом как-нибудь собрать всё это воедино, но это сильно некрасиво смотрится. Есть какое-нибудь приличное решение?
Несколько часов пришлось поломать голову, но в итоге решение получилось таким.
Таблица с исходными данными.
| 1 2 3 4 5 | CREATE TABLE [dbo].[tmp]( [Agent] [INT] NULL, [Price] [INT] NULL, [DATE] [datetime] NOT NULL ) ON [PRIMARY] |
| Agent | Price | Date |
| 1 | 100 | 2013-06-01 00:00:00.000 |
| 1 | 100 | 2013-06-02 00:00:00.000 |
| 2 | 200 | 2013-06-02 00:00:00.000 |
| 2 | 200 | 2013-06-05 00:00:00.000 |
| 2 | 200 | 2013-06-06 00:00:00.000 |
| 2 | 200 | 2013-06-07 00:00:00.000 |
| 1 | 300 | 2013-06-08 00:00:00.000 |
| 1 | 300 | 2013-06-12 00:00:00.000 |
| 1 | 200 | 2013-06-13 00:00:00.000 |
| 1 | 200 | 2013-06-14 00:00:00.000 |
| 2 | 200 | 2013-06-14 00:00:00.000 |
| 2 | 200 | 2013-06-13 00:00:00.000 |
Создаем вьюшку, где для каждой даты из исходной таблицы находим запись о предыдущем дне из той же таблицы. Получаем пары идущих друг за другом дней, будем использовать ее в дальнейшем.
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | CREATE VIEW [dbo].[agent_dates] AS SELECT DISTINCT s2.Past, s1.Today FROM ( SELECT [DATE] AS Today FROM [cck_test].[dbo].[tmp] ) AS s1 LEFT JOIN ( SELECT [DATE] AS Past FROM [cck_test].[dbo].[tmp] ) AS s2 ON Today = dateadd(DAY, 1, Past) GO ) ON [PRIMARY] |
| Past | Today |
| NULL | 2013-06-01 00:00:00.000 |
| NULL | 2013-06-05 00:00:00.000 |
| NULL | 2013-06-12 00:00:00.000 |
| 2013-06-01 00:00:00.000 | 2013-06-02 00:00:00.000 |
| 2013-06-05 00:00:00.000 | 2013-06-06 00:00:00.000 |
| 2013-06-06 00:00:00.000 | 2013-06-07 00:00:00.000 |
| 2013-06-07 00:00:00.000 | 2013-06-08 00:00:00.000 |
| 2013-06-12 00:00:00.000 | 2013-06-13 00:00:00.000 |
| 2013-06-13 00:00:00.000 | 2013-06-14 00:00:00.000 |
Используем CTE-выражение для вычисления на каждую дату количество последующих дней без рызрывов (количество дней — Datalevel, находим длину периодов)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | WITH CTE (Past, Today, Datalevel) AS ( SELECT f1.Past, f1.Today, 0 AS Datalevel FROM [cck_test].[dbo].[agent_dates] f1 UNION ALL SELECT f2.Past, f2.Today, Datalevel+1 FROM [cck_test].[dbo].[agent_dates] f2 INNER JOIN CTE ON f2.Today = CTE.Past ) |
| Past | Today | Datalevel |
| NULL | 2013-06-01 00:00:00.000 | 0 |
| NULL | 2013-06-01 00:00:00.000 | 1 |
| 2013-06-01 00:00:00.000 | 2013-06-02 00:00:00.000 | 0 |
| NULL | 2013-06-05 00:00:00.000 | 0 |
| NULL | 2013-06-05 00:00:00.000 | 3 |
| NULL | 2013-06-05 00:00:00.000 | 2 |
| NULL | 2013-06-05 00:00:00.000 | 1 |
| 2013-06-05 00:00:00.000 | 2013-06-06 00:00:00.000 | 0 |
| 2013-06-05 00:00:00.000 | 2013-06-06 00:00:00.000 | 2 |
| 2013-06-05 00:00:00.000 | 2013-06-06 00:00:00.000 | 1 |
| 2013-06-06 00:00:00.000 | 2013-06-07 00:00:00.000 | 0 |
| 2013-06-06 00:00:00.000 | 2013-06-07 00:00:00.000 | 1 |
| 2013-06-07 00:00:00.000 | 2013-06-08 00:00:00.000 | 0 |
| NULL | 2013-06-12 00:00:00.000 | 0 |
| NULL | 2013-06-12 00:00:00.000 | 2 |
| NULL | 2013-06-12 00:00:00.000 | 1 |
| 2013-06-12 00:00:00.000 | 2013-06-13 00:00:00.000 | 0 |
| 2013-06-12 00:00:00.000 | 2013-06-13 00:00:00.000 | 1 |
| 2013-06-13 00:00:00.000 | 2013-06-14 00:00:00.000 | 0 |
Находим записи с максимальной продолжительностью периода на каждую дату, у которых нет вчерашнего дня (это будет начало периода). Добавляем полученную продолжительность (Datalevel) как количество дней к дате и получаем конец периода.
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | SELECT Today AS START, DATEADD(dd,n,Today) AS Finish FROM ( SELECT Today, MAX(Datalevel) AS n FROM ( SELECT DISTINCT * FROM CTE WHERE Past IS NULL ) t1 GROUP BY Today ) t2 ORDER BY Today |
Все, мы получили непрерывные периоды, для которых есть записи в исходной таблице.
| Start | Finish |
| 2013-06-01 00:00:00.000 | 2013-06-02 00:00:00.000 |
| 2013-06-05 00:00:00.000 | 2013-06-08 00:00:00.000 |
| 2013-06-12 00:00:00.000 | 2013-06-14 00:00:00.000 |
jeux en ligne gratuit machines à sous bonus casinos
fominoleg.ru