Поля AutoIncrement в базах данных без поля автоинкремента. Ms sql автоинкрементное поле
Автоинкрементные поля в MS SQL
Вниз
Автоинкрементные поля в MS SQL
kaif © (2008-09-08 00:49) [0]Обычно в IB Или ORACLE для этой цели я юзал генераторы. Генератор - вещь понятная. По сути это глобальная переменная вне контекста транзакции.
В MSSQL для этой цели предлагается юзать тип поля IDENTITY.А после вставки проверять значение глобальной переменной @@IDENTITY, которая хранит значение "последнего" значения присвоенного полю IDENTITY в данной сессии.
Казалось бы, какие тут могут быть грабли?Все было великолепно, пока я не замучился отлаживать одно место, где у меня все время возникала ошибка нарушения ссылочной целостности.
Вот, что я делал в хранимой процедуре:
1. Вставляю запись в главную таблицу.2. Сохраняю @@IDENTITY во временной переменной3. В цикле пытаюсь вставить записи в подчиненную, используя сохраненное значение IDENTITY в локальной переменной.
На самом же деле происходило следующее. По условиям техзадания мне нужно было зачем-то в триггере той самой главной таблицы сделать инсерт еще в одну таблицу. И этот триггер делал этот инсерт. И вот он-то и портил "последнее значение" глобальной переменной @@IDENTITY, так как в той таблице тоже есть полде типа IDENTITY.
Вот такой вот интересный маразм получается. Если кто-то повесит триггер на таблицу, который вставит что-то в другую таблицу, то закончиться это может потерей правильного значения @@IDENTITY . Причем откуда его тогда брать, уже неизвестно. Похоже нужно воспользоваться запросом по альтернативному ключу к вставленной записи. Но тогда лучше вообще не юзать эту глобальную переменную @@IDENTITY. Или строго-настрого запретить себе и всем остальным что-либо вставлять из триггеров куда-либо. Даже в таблицу логов, если кто-то захочет. А то вдруг какая-то процедура юзает этот @@IDENTITY и он будет запорчен?
Вот так вот.
Готов выслушать битье ногами по полной программе. Просто 10 минут смотрел как ошалелый на то, как "сразу после вставки" в тексте процедуры @@IDENTITY меняет свое значение до неузнаваемости. Пока сообразил, что происходит.
> Вот, что я делал в хранимой процедуре:т.е. ничего? тут одни слова, в процедуре это не более чем коментарии.
> Причем откуда его тогда брать, уже неизвестно.известно. в справке написано, если пройти по ссылкам из @@IDENTITY.но ты опять просился делать "по аналогиям" не читая как оно на самом деле...
> Но тогда лучше вообще не юзать эту глобальную переменную @@IDENTITY.это как ложка, в обед ее очень полезно юзать, во время секса она практически бесполезна и лучше ее не юзать, а у Нео ее вообще нет...
sniknik © (2008-09-08 01:35) [2]> просилсябросился
Германн © (2008-09-08 01:52) [3]> а у Нео ее вообще нет...Это как? Он что, палочками пользуется?:)
kaif © (2008-09-08 03:26) [4]sniknik © (08.09.08 01:31) [1] > Вот, что я делал в хранимой процедуре:т.е. ничего? тут одни слова, в процедуре это не более чем коментарии.
Я думал, что хотя бы здесь я с людьми беседую, а не с SQL-сервером.:)
Вариант (2008-09-08 08:12) [5]> kaif © (08.09.08 00:49)SCOPE_IDENTITY
Электронная документация по MSSQL Server 2005
"...Допуская, что столбец идентификаторов имеется в обеих таблицах, T1 и T2, функции @@IDENTITY и SCOPE_IDENTITY вернут разные значения в конце инструкции INSERT в таблице T1. Функция @@IDENTITY возвращает значение столбца идентификаторов, добавленное в текущем сеансе последним во всех областях. Это значение, вставленное в таблицу T2. Функция SCOPE_IDENTITY() возвратит значение IDENTITY, вставленное в таблицу T1. Это было последним добавлением, произошедшим в заданной области. Функция SCOPE_IDENTITY() вернет значение NULL, если функция была вызвана до того, как какая-либо инструкция INSERT была выполнена для столбца идентификаторов в этой области..."
Anatoly Podgoretsky © (2008-09-08 08:35) [6]> kaif (08.09.2008 0:49:00) [0]
Читаешь BOL по теме @@IDENTITY и смотришь See ALso по двум другим фунциям из данного раздела, затем выбираешь нужную.
Медвежонок Пятачок © (2008-09-08 09:07) [7]на 2005 вообще есть ретурн параметры после инсерта/апдейта. но это скорее для "на клиенте"
sniknik © (2008-09-08 11:27) [8]> Это как? Он что, палочками пользуется?внутривенно.
Форум: "Базы";Поиск по всему сайту: www.delphimaster.net;Текущий архив: 2009.05.17;Скачать: [xml.tar.bz2];Память: 0.76 MBВремя: 0.028 c
www.delphimaster.net
поле SQL AUTO ИНКРЕМЕНТ
Автоинкрементная в новой записи будет генерировать уникальный номер в таблицу во.
Поле AUTO ИНКРЕМЕНТ
Как правило, мы хотим, чтобы вставить новую запись каждый раз, автоматически создает значение поля первичного ключа.
Мы можем создать поле Автоинкрементная в таблице.
Синтаксис для MySQL
Следующий SQL заявление "Лица" таблицы в столбце "ИД" определяется как поля первичного ключа автоинкрементируемого:
CREATE TABLE Persons ( ID int NOT NULL AUTO_INCREMENT, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255), PRIMARY KEY (ID) )
MySQL использует ключевое слово AUTO_INCREMENT для выполнения автоинкрементным.
По умолчанию начальное значение AUTO_INCREMENT равно 1, и увеличивается на 1 для каждой новой записи.
Пусть последовательность AUTO_INCREMENT начать с другого значения, используйте следующий синтаксис SQL:
ALTER TABLE Persons AUTO_INCREMENT=100
Для того, чтобы вставить новую запись в таблице "Лица", мы не должны "ID" столбец заранее заданное значение (автоматически добавляет уникальное значение):
INSERT INTO Persons (FirstName,LastName) VALUES ('Lars','Monsen')
SQL выше утверждение будет вставить новую запись в таблице "Лица". колонка "ID" присваивается уникальное значение. Колонка "FirstName" будет установлен в положение "Ларс", колонка "LastName" будет установлен в положение "MONSEN".
Синтаксис для SQL Server
Следующий SQL заявление "Лица" таблицы в столбце "ИД" определяется как поля первичного ключа автоинкрементируемого:
CREATE TABLE Persons ( ID int IDENTITY(1,1) PRIMARY KEY, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255) )
MS SQL Server, используя ключевое слово IDENTITY выполнить Автоинкрементная.
В приведенном выше примере, начало значение тождественности равно 1, и увеличивается на 1 для каждой новой записи.
Совет: Чтобы указать столбец "ID" к исходным шагом 10 и 5, пожалуйста идентичность персонами (10,5).
Для того, чтобы вставить новую запись в таблице "Лица", мы не должны "ID" столбец заранее заданное значение (автоматически добавляет уникальное значение):
INSERT INTO Persons (FirstName,LastName) VALUES ('Lars','Monsen')
SQL выше утверждение будет вставить новую запись в таблице "Лица". колонка "ID" присваивается уникальное значение. Колонка "FirstName" будет установлен в положение "Ларс", колонка "LastName" будет установлен в положение "MONSEN".
Синтаксис для доступа
Следующий SQL заявление "Лица" таблицы в столбце "ИД" определяется как поля первичного ключа автоинкрементируемого:
CREATE TABLE Persons ( ID Integer PRIMARY KEY AUTOINCREMENT, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255) )
MS Access, используя ключевое слово AUTOINCREMENT выполнить Автоинкрементная.
По умолчанию начальное значение AUTOINCREMENT равно 1, и увеличивается на 1 для каждой новой записи.
Совет: Чтобы указать столбец "ID" к исходной с шагом 10 и 5, пожалуйста , Autoincrement к Autoincrement (10,5).
Для того, чтобы вставить новую запись в таблице "Лица", мы не должны "ID" столбец заранее заданное значение (автоматически добавляет уникальное значение):
INSERT INTO Persons (FirstName,LastName) VALUES ('Lars','Monsen')
SQL выше утверждение будет вставить новую запись в таблице "Лица". колонка "ID" присваивается уникальное значение. Колонка "FirstName" будет установлен в положение "Ларс", колонка "LastName" будет установлен в положение "MONSEN".
Синтаксис для Oracle
В Oracle, код немного сложнее.
Необходимо создать Автоинкрементная поля от объекта последовательности (который генерирует последовательность цифр).
Пожалуйста, используйте следующий синтаксис CREATE SEQUENCE:
CREATE SEQUENCE seq_person MINVALUE 1 START WITH 1 INCREMENT BY 1 CACHE 10
Приведенный выше код создает объект последовательности под названием seq_person, который, начиная с 1 и увеличивается на 1. Значения кэша объектов 10 для повышения производительности. Кэш опция обеспечивает быстрый доступ к числу значений последовательности, которые будут сохранены.
Для того, чтобы вставить новую запись в таблице "Лица", мы должны использовать NEXTVAL функцию (эта функция возвращает следующее значение из последовательности seq_person):
INSERT INTO Persons (ID,FirstName,LastName) VALUES (seq_person.nextval,'Lars','Monsen')
SQL выше утверждение будет вставить новую запись в таблице "Лица". столбец "ID" присвоен следующий номер в последовательности из seq_person. Колонка "FirstName" будет установлен в положение "Ларс", колонка "LastName" будет установлен в положение "MONSEN".
www.w3big.com
Поля AutoIncrement в базах данных без поля автоинкремента
Механизм генерации уникальных идентификационных значений не должен быть подвержен изоляции транзакций. Это необходимо для того, чтобы база данных генерировала отдельное значение для каждого клиента, лучше, чем трюк SELECT MAX(id)+1 FROM table, что приводит к условию гонки, если два клиента пытаются одновременно присвоить новые значения id.
Вы не можете имитировать эту операцию, используя стандартные SQL-запросы (если вы не используете блокировки таблиц или serializable транзакций). Это должен быть механизм, встроенный в механизм базы данных.
ANSI SQL не описал операцию генерации уникальных значений для суррогатных ключей до SQL: 2003. До этого не было стандарта для автоинкрементных столбцов, поэтому почти каждая марка RDBMS предоставила некоторое частное решение. Естественно, они сильно различаются, и нет возможности использовать их простым, независимым от базы данных способом.
- MySQL имеет возможность AUTO_INCREMENT столбца или SERIAL псевдо-типа данных, которое эквивалентно BIGINT UNSIGNED AUTO_INCREMENT;
- Microsoft SQL Server имеет параметр столбца IDENTITY и NEWSEQUENTIALID(), который является чем-то вроде автоматического увеличения и GUID;
- У Oracle есть объект SEQUENCE;
- PostgreSQL имеет объект SEQUENCE или SERIAL псевдо-тип данных, который неявно создает объект последовательности в соответствии с соглашением об именах;
- InterBase/Firebird имеет объект GENERATOR, который в значительной степени похож на SEQUENCE в Oracle; Жар-птица 2.1 поддерживает SEQUENCE;
- SQLite рассматривает любое целое число, объявленное как ваш первичный ключ, как неявное автоинкремент;
- DB2 UDB имеет практически все: SEQUENCE объектов, или вы можете объявить столбцы с опцией «GEN_ID».
Все эти механизмы работают за пределами изоляции транзакций, гарантируя, что одновременные клиенты получат уникальные значения. Также во всех случаях есть способ запросить последнее генерируемое значение для вашего текущего сеанса. Должно быть, поэтому вы можете использовать его для вставки строк в дочернюю таблицу.
stackoverrun.com
[ansi-sql] Поля AutoIncrement в базах данных без поля автоинкремента [auto-increment] [sql-server]
Механизм генерации уникальных идентификационных значений не должен подвергаться изоляции транзакций. Это необходимо для того, чтобы база данных генерировала отдельное значение для каждого клиента, лучше, чем трюк SELECT MAX(id)+1 FROM table , что приводит к условию гонки, если два клиента пытаются одновременно присвоить новые значения id .
Вы не можете имитировать эту операцию, используя стандартные SQL-запросы (если вы не используете блокировки таблиц или сериализуемые транзакции). Это должен быть механизм, встроенный в механизм базы данных.
ANSI SQL не описал операцию для генерации уникальных значений для суррогатных ключей до SQL: 2003. До этого не было стандарта для автоинкрементных столбцов, поэтому почти каждая марка RDBMS предоставила некоторое частное решение. Естественно, они сильно различаются, и нет возможности использовать их простым, независимым от базы данных способом.
- MySQL имеет параметр столбца AUTO_INCREMENT или псевдодальный тип SERIAL который эквивалентен BIGINT UNSIGNED AUTO_INCREMENT ;
- Microsoft SQL Server имеет параметр столбца IDENTITY и NEWSEQUENTIALID() который является чем-то вроде auto-increment и GUID;
- Oracle имеет объект SEQUENCE ;
- PostgreSQL имеет объект SEQUENCE или псевдодальный тип SERIAL который неявно создает объект последовательности в соответствии с соглашением об именах;
- InterBase / Firebird имеет объект GENERATOR который в значительной степени похож на SEQUENCE в Oracle; Firebird 2.1 поддерживает SEQUENCE ;
- SQLite рассматривает любое целое число, объявленное как ваш первичный ключ, как неявное автоинкремент;
- DB2 UDB имеет почти все: объекты SEQUENCE , или вы можете объявлять столбцы с GEN_ID « GEN_ID ».
Все эти механизмы работают за пределами изоляции транзакций, гарантируя, что одновременные клиенты получат уникальные значения. Также во всех случаях есть способ запросить последнее генерируемое значение для вашего текущего сеанса . Должно быть, поэтому вы можете использовать его для вставки строк в дочернюю таблицу.
В большинстве баз данных, которые не имеют полей автоинкремента, таких как SQL Server (я имею в виду Oracle конкретно), есть последовательности, в которых вы запрашиваете последовательность для следующего числа. Независимо от того, сколько людей запрашивает номера одновременно, каждый получает уникальный номер.
Если вам нужно поле с автоинкрементами с непервичными ключами, очень приятное MySQL-решение для создания последовательностей арбитража - использовать относительно неизвестную last_insert_id(expr) .
Если expr задано как аргумент LAST_INSERT_ID (), значение аргумента возвращается функцией и запоминается как следующее значение, которое должно быть возвращено LAST_INSERT_ID (). Это можно использовать для моделирования последовательностей ...
(из http://dev.mysql.com/doc/refman/5.1/en/information-functions.html#function_last-insert-id )
Вот пример, который демонстрирует, как можно сохранить вторичную последовательность для нумерации комментариев для каждого сообщения:
CREATE TABLE `post` ( `id` INT(10) UNSIGNED NOT NULL, `title` VARCHAR(100) NOT NULL, `comment_sequence` INTcode-examples.net
Свойство таблицы IDENTITY INSERT в Microsoft SQL Server | Info-Comp.ru
Как видно из названия материала сегодня я расскажу о таком, в некоторых случаях, полезном свойстве таблицы в Microsoft SQL Server как IDENTITY_INSERT, используя именно это свойство можно вставить в автоинкрементное поле значение, которое ранее было удалено, т.е. заполнить или восстановить пропущенные значения идентификаторов.
Наверное у многих программистов SQL сервера возникала ситуация когда в таблице в которой определена спецификация идентификатора по какой-то причине удаляются некоторые записи, а затем возникает необходимость восстановить эти записи, причем со значениями старых идентификаторов. Первое что приходит на ум это конечно удалить идентификацию, вставить строки с необходимыми значениями, а затем восстановить идентификацию, но для этого, как вы понимаете, необходимо выполнить достаточно много манипуляций, которые могут повлиять на ход текущей работы, поэтому это нужно делать быстро, да и лучше в тот момент, когда в базе данных нет работающих пользователей.
Но на самом деле есть более простой, а главное правильный способ, который позволяет вставлять значения в столбец идентификаторов таблицы, он заключается в использование свойства IDENTITY INSERT.
Свойство IDENTITY_INSERT в MS SQL Server
IDENTITY_INSERT – это свойство таблицы, которое позволяет вставлять явные значения в столбец идентификаторов таблицы т.е. в автоинкрементное поле. Значение вставляемого идентификатора может быть как меньше текущего значения, так и больше, например, для того чтобы пропустить определенный интервал значений.
При работе с данным свойством необходимо учитывать некоторые нюансы, давайте их рассмотрим:
- Свойство IDENTITY_INSERT может принимать значение ON только для одной таблицы в сеансе, т.е. одновременно для двух и более таблиц в сеансе нельзя выставить IDENTITY_INSERT в ON. Если необходимо в одной SQL инструкции использовать IDENTITY_INSERT ON для нескольких таблиц, нужно сначала выставить значение в OFF у таблицы, которая уже обработана, а затем установить IDENTITY_INSERT в ON для следующей таблицы;
- Если значение идентификатора, которое вставляется больше текущего значения, то SQL сервер автоматически будет использовать вставленное значение в качестве текущего, т.е. если например, следующее значение идентификатора 5, а Вы, используя IDENTITY INSERT, вставляете идентификатор со значением 6, то автоматически следующим значением идентификатора станет значение 7;
- Для того чтобы использовать IDENTITY_INSERT пользователь должен иметь соответствующие права, а именно быть владельцем объекта или входить в состав роли сервера sysadmin, роли базы данных db_owner или db_ddladmin.
Итак, давайте рассмотрим ситуацию, когда у нас возникла необходимость вставить значение в столбец с идентификатором, допустим, строка с этим значением была удалена, а нам ее нужно восстановить.
Для начала давайте рассмотрим исходные данные.
Исходные данные
Примечание! В качестве примера у меня будет выступать СУБД Microsoft SQL Server 2012 Express.
Создаем таблицу, в которой есть столбец с идентификатором и заполняем ее данными.
CREATE TABLE TestTable( ID INT IDENTITY(1,1) NOT NULL PRIMARY KEY, TextData VARCHAR(50) NOT NULL ) GO INSERT INTO TestTable (TextData) VALUES ('Строка 1') INSERT INTO TestTable (TextData) VALUES ('Строка 2') INSERT INTO TestTable (TextData) VALUES ('Строка 3') INSERT INTO TestTable (TextData) VALUES ('Строка 4') INSERT INTO TestTable (TextData) VALUES ('Строка 5') GO SELECT * FROM TestTable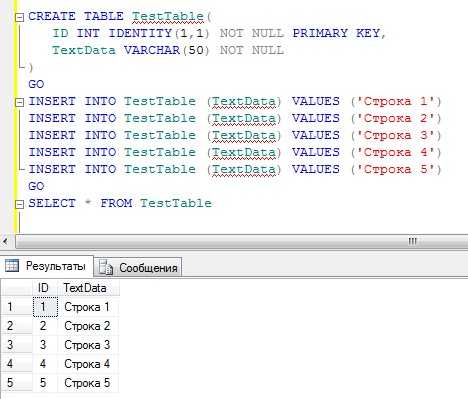
Затем давайте удалим строку, в которой значение идентификатора равняется 3.
DELETE TestTable WHERE TextData = 'Строка 3' GOВосстановление строк таблицы с автоинкрементным полем
У нас в таблице отсутствует строка со значение ID = 3 и нам ее нужно восстановить именно с ID = 3, для этого мы как начинающие программисты SQL пробуем сначала так
INSERT INTO TestTable (ID, TextData) VALUES (3, 'Строка 3') GOКак видим, у нас не получилось вставить такую строку.
Теперь давайте, используем свойство IDENTITY_INSERT, т.е. выставим его значение для таблицы TestTable в ON.
SET IDENTITY_INSERT TestTable ON INSERT INTO TestTable (ID, TextData) VALUES (3, 'Строка 3') SELECT * FROM TestTable GO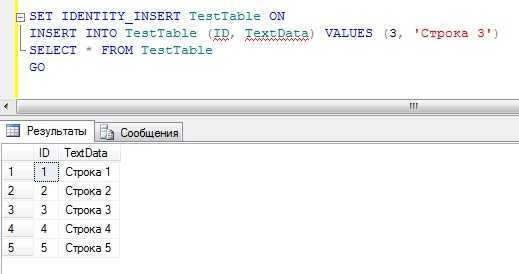
На этот раз все прошло как надо.
Примечание! Если столбец с идентификатором является первичным ключом как в нашем примере, то при попытке вставить значение идентификатора, которое уже есть, сработает ограничение PRIMARY KEY, другими словами уникальные ключи продолжают действовать.
Заметка! Начинающим программистам рекомендую почитать мою книгу «Путь программиста T-SQL», в ней я подробно, с большим количеством примеров, рассказываю про другие полезные возможности языка Transact-SQL.
На этом у меня все, надеюсь, материал был Вам полезен!
Похожие статьи:
info-comp.ru
Q&A - К вопросу об идентификаторах
Автоинкременты и все, все, все…
Автор: Иван БодягинThe RSDN GroupИсточник: RSDN Magazine #1-2004
Опубликовано: 07.02.2004Исправлено: 10.12.2016Версия текста: 1.3 «Ну вот, и меня посчитали…» (с) МультикО чем речь
Уникальная идентификация записей в таблице, является практически основой реляционных СУБД. Вообще в реляционной теории предполагается, что если две записи ни чем друг от друга не отличаются, то это явная избыточность, и количество таких записей можно сократить до одной. Собственно вопросам этой самой идентификации, каковых возникает на удивление много, и посвящен этот FAQ.
Идентификация
Как уже говорилось уникальная идентификация записей – это основа реляционных СУБД. Вообще данный вопрос довольно тесно связан с давним теоретическим спором «Суррогатные ключи» vs. «Естественные ключи». Но поскольку существует замечательная статья Анатолия Тенцера “Естественные ключи против искуственных ключей”, то не думаю, что здесь имеет смысл освещать этот вопрос. Вне зависимости от используемого подхода, очень часто, по тем или иным причинам, данные, относящиеся непосредственно к приложению, не удается заведомо однозначно разделить по записям. И логично, что в таких случаях прибегают к помощи сервера, который генерирует искусственные идентификаторы для каждой записи.
Особого внимания заслуживает термин «уникальный». Уникальность серверного идентификатора имеет свои границы. В каких-то случаях гарантируется уникальность в пределах таблицы, то есть если не предпринимать специальных усилий, то есть шанс получить одинаковые идентификаторы в разных таблицах, что не всегда приемлемо. В каких-то случаях этот идентификатор гарантировано уникален в пределах БД, чего тоже не всегда бывает достаточно. И, наконец, есть идентификаторы, гарантирующие уникальность в пределах всех СУБД вообще…
Способ генерации и вид этого идентификатора стандартом не оговорен, да и вообще стандарт подобными мелочами не занимается, поэтому каждый производитель СУБД реализует эту функциональность так, как ему удобно. В итоге, мы имеем потрясающий набор различных способов, выудить из сервера уникальный идентификатор, беда только в том, что у каждого сервера этот способ свой. Однако, несмотря на все многообразие подходов, практически во всех СУБД, в том или ином виде, реализована автоматическая генерация последовательных идентификаторов, это так называемые «автоинкременты». Иными словами, при обращении к серверу за таким идентификатором гарантируется, что возвращенное число будет больше, чем число, полученное при предыдущем обращении.
| ПРИМЕЧАНИЕ Говоря «больше», я несколько упрощаю. В принципе, в большинстве СУБД, ничто не мешает задать и отрицательное приращение. То есть, правильнее было бы сказать, что каждое последующее число отличается от предыдущего на величину заданного приращения, которое вполне может быть отрицательным, но думаю, что в данном случае лучше упростить. |
Microsoft SQL Server
Эта СУБД предоставляет два способа получить обеспечить уникальность записи. Один работает в пределах таблицы и является автоинкрементным, а другой замахивается на уникальность «вообще», и в принципе подобное решение покрывает практически все потребности в уникальных идентификаторах.
Автоинкремент
Начнем с обычного автоинкремента. В отличие от большинства других СУБД, здесь эта функциональность реализована не в виде отдельной функции, а в виде свойства таблицы, поэтому и гарантируется уникальность лишь в пределах таблицы, а не БД или экземпляра сервера. Для того чтобы не болела голова об уникальности записей, один из столбцов в таблице объявляется идентификатором, после этого, при добавлении каждой новой записи, в этом столбце автоматически появляется число, которое заведомо больше, чем то, которое было сгенерировано для предыдущей добавленной записи. Вообще здесь есть ряд тонкостей, но о них чуть позже.
Итак, при объявлении столбца уникальным, с помощью ключевого слова IDENTITY устанавливается начальное значение и величина, на которую будет это значение увеличиваться при добавлении каждой записи.
| IDENTITY [ ( seed , increment ) ] |
Здесь, как не сложно догадаться, seed – это самое первое значение, а increment – это величина, которая каждый раз будет прибавляться к предыдущему значению. По умолчанию seed и increment равны единице, то есть выставить у столбца свойство IDENTITY, равноценно выставлению IDENTITY(1,1). Ключевое слово IDENTITY может быть указано при создании CREATE TABLE, или изменении таблицы ALTER TABLE. При этом тип столбца должен быть tinyint, smallint, int, bigint, decimal(p,0) или numeric(p,0), то есть автоникремент должен быть целочисленным. Следует так же помнить, что только один столбец может быть объявлен IDENTITY. Таким образом, создание таблицы с автоинкрементным полем выглядит примерно так:
| CREATE TABLE Ident_table (ID int IDENTITY(1, 1), some_values varchar(50)) |
Здесь столбец ID объявлен автоинкрементным, и при каждом добавлении новой записи в таблицу, в него автоматически будет записываться новое число, хотя бы на единицу большее того, что было записано при предыдущем добавлении.
| INSERT INTO Ident_table (some_values) VALUES ('value 1') INSERTINTO Ident_table (some_values) VALUES ('value 2') SELECT * FROM Ident_table ID some_values ----------- -------------------------------------------------- 1 value 1 2 value 2 (2 row(s) affected) |
При этом явно писать значения в автоинкрементное поле нельзя, произойдет ошибка, и оператор вставки не отработает.
| INSERT INTO Ident_table (ID, some_values) VALUES (3, 'value 2') Cannot insert explicit value for identity column in table 'Ident_table' when IDENTITY_INSERT is set to OFF. |
Однако прямо в сообщении об ошибке есть подсказка как это ограничение обойти. Для того чтобы писать напрямую в автоинкрементный столбец, необходимо установить свойство IDENTITY_INSERT в ON.
| SET IDENTITY_INSERT Ident_table ON GO INSERTINTO Ident_table (ID, some_values) VALUES (5, 'value 5') SELECT * FROM Ident_table ID some_values ----------- -------------------------------------------------- 1 value 1 2 value 2 5 value 3 (3 row(s) affected) |
Но здесь другая тонкость, если при отключенной автогенерации не указать явно, какое значение необходимо вставить в автоинкрементное поле, то вставка опять-таки успехом не увенчается.
| INSERT INTO Ident_table (some_values) VALUES ('value 4') Explicit value must be specified for identity column in table 'Ident_table' when IDENTITY_INSERT is set to ON. |
Таким образом, возможно два варианта заполнения автоинкрементного столбца, либо этим занимается сервер, и тогда невозможно явно изменить значение в этом поле, либо это делается вручную, но тогда это поле обязательно к заполнению.
| ПРЕДУПРЕЖДЕНИЕ Следует помнить, что если автоинкрементное поле заполняется самостоятельно и на это поле не установлено никаких дополнительных требований уникальности, то запросто можно записать туда несколько одинаковых значений. |
Если же теперь опять вернуть серверу возможность вставлять номера в автоинкрементное поле, то следующее значение будет больше, на число указанное в increment при создании столбца, самого большого значения в этом поле. Не важно вручную было введено это самое большое значение или сгенерировано сервером.
| SET IDENTITY_INSERT Ident_table ON GO INSERTINTO Ident_table (some_values) VALUES ('value 4') SELECT * FROM Ident_table ID some_values ----------- -------------------------------------------------- 1 value 1 2 value 2 5 value 3 6 value 4 (4 row(s) affected) |
Все это конечно здорово, но, как правило, просто уникально идентифицировать запись недостаточно, необходимо еще связать эту запись с записью из другой таблицы по этому самому идентификатору. А для этого надо уметь получать этот идентификатор сразу же после его генерации. Для выполнения этой задачи в Microsoft SQL Server существуют 3 функции: @@IDENTITY, SCOPE_IDENTITY() и IDENT_CURRENT().
Функция @@IDENTITY возвращает последнее значение, записанное севером в автоинкрементный столбец в текущей сессии. Что это означает? Если между вызовом INSERT и вызовом @@IDENTITY успеет пролезть вставка из другой сессии, то @@IDENTITY вернет идентификатор, который был записан при первой вставке. То есть, при пользовании @@IDENTITY нет необходимости заботиться о том, что параллельные вставки будут мешать друг другу при получении правильных идентификаторов, сервер все сделает сам.
| INSERT INTO Ident_table (some_values) VALUES ('value 5') INSERTINTO Ident_table (some_values) VALUES ('value 6') SELECT @@IDENTITYas [Last ID in session] SELECT * FROM Ident_table Last ID in session ---------------------------------------- 7 (1 row(s) affected) ID some_values ----------- ---------------------------- ... ... 6 value 4 7 value 5 8 value 6 (6 row(s) affected) |
Все замечательно, но в подобном подходе с сессиями есть один, довольно серьезный недостаток. Если на таблице с автоинкрементным столбцом висит какой-нибудь триггер на вставку, который, в свою очередь, что-то кому-то вставляет, то @@IDENTITY вернет не значение, записанное сервером в оригинальную таблицу, а то значение, которое будет записано после второй вставки в триггере, так как формально это все еще та же сессия.
Для того чтобы избежать таких неприятностей, служит SCOPE_IDENTITY(), который возвращает значение, записанное сервером в автоинкрементный столбец не только в рамках сессии, но и в рамках текущего пакета (batch).
| CREATE TABLE Ident2(ID int IDENTITY(0, -2), value varchar(50)) GO CREATETRIGGER IdentTrigger ON Ident_table FORINSERTASINSERTINTO Ident2 (value) VALUES(GetDate()) GO INSERTINTO Ident_table (some_values) VALUES ('value 7') SELECT@@IDENTITYas [Last ID in session (@@IDENTITY)] SELECTSCOPE_IDENTITY()as [Last ID in batch (SCOPE_IDENTITY())] SELECT * FROM Ident_table Last ID in session (@@IDENTITY) ---------------------------------------- 0 Last ID in batch (SCOPE_IDENTITY()) ---------------------------------------- 9 ID some_values ----------- ---------------------------- ... ... 8 value 6 9 value 7 (7 row(s) affected) |
IDENT_CURRENT(), в свою очередь, не обращает ни какого внимания ни на сессии, ни на пакеты, а просто возвращает последнее число записанное сервером в автоинкрементное поле в указанной таблице. Естественно, в данном случае запросто можно получить идентификатор, сгенерированный сервером для другой сессии.
| INSERT INTO Ident_table (some_values) VALUES ('value 8') INSERTINTO Ident_table (some_values) VALUES ('value 9') SELECT@@IDENTITYas [Last ID in session], SCOPE_IDENTITY()as [Last ID in batch], IDENT_CURRENT('Ident_table')as [Last ID in IdentTable] SELECT * FROM Ident_table SELECT * FROM Ident2 Last ID in session Last ID in batch Last ID in IdentTable ------------------ ---------------- --------------------- -2 10 11 ID some_values ----------- ---------------------------------------------- ... ... 9 value 7 10 value 8 11 value 9 (9 row(s) affected) ID value ----------- ---------------------------------------------- 0 1961-02-01 19:15 -2 1961-02-01 19:30 (2 row(s) affected) |
Собственно этот пример и демонстрирует различия всех трех способов получения записанного сервером значения автоинкремента. Эти способы покрывают практически все потребности в автоинкрементах, которые могут возникнуть при разработке.
Однако следует учитывать еще ряд нюансов. Во-первых, очевидно, что никто не гарантирует отсутствия «дырок» при автоматической генерации значений в столбце. А, во вторых, генерация нового значения для автоинкремента выполняется в не явной автономной транзакции. Это означает, что если сама по себе операция добавления записи не увенчается успехом, или транзакция, в которой будет производиться добавление, закончится отменой, то сервер следующее автоинкрементное значение сгенерирует так, как будто бы предыдущее добавление новой записи произошло успешно. И таким образом, образуется разрыв в автоматической нумерации.
| BEGIN TRAN INSERT INTO Ident_table (some_values) VALUES ('value 10') ROLLBACK INSERTINTO Ident_table (some_values) VALUES ('value 11') SELECT * FROM Ident_table ID some_values ----------- -------------------------------------------------- ... ... 10 value 8 11 value 9 13 value 11 (10 row(s) affected) |
И можно наблюдать разрыв в идентификации записей.
И еще один нюанс, даже если удалить все записи из таблицы, последующие идентификаторы, возвращаемые сервером, не обнулятся, а будут продолжать увеличиваться, как будто записи не удалялись. В некоторых случаях может понадобиться обнулить серверный генератор последовательностей или проинициализировать его каким-нибудь другим значением. Для этих целей существует системная функция DBCC CHECKIDENT. С ее помощью можно проверить счетчик «на правильность» и/или проинициализировать его новым значением. Если же необходимо сбросить счетчик в начальное значение при удалении всех записей, то можно воспользоваться не оператором DELETE, а оператором TRUNCATE. В этом случае счетчик автоматически сбросится в первоначальное значение, но следует помнить, что TRUNCATE нельзя пользоваться, если на таблицу ссылаются внешние ключи других таблиц.
Существуют так же специальные команды, с помощью которых можно узнать начальное значение генератора определенной таблицы и приращение, то есть те значения, которые были установлены при указании IDENTITY. Это IDENT_INCR и IDENT_SEED соответственно.
Таким образом, в свете всего вышесказанного, самый типичный сценарий применения автоинкремента выглядит примерно так:
| DECLARE @PrimaryKey int BEGINTRANINSERTINTO MasterTbl (<... some fields ...>) VALUES (<... some values ...>) SET @PrimaryKey = SCOPE_IDENTITY()INSERTINTO DetailTbl (ForeignKey, <... some other fields ...>) VALUES (@PrimaryKey, <...some other values ...>) COMMIT |
Глобальный идентификатор
Идентификатор в пределах таблицы – это конечно здорово, но отнюдь не предел мечтаний. В некоторых случаях вовсе не лишней была бы возможность получить запись, гарантировано уникальную в пределах базы данных, экземпляра сервера или даже в пределах всех серверов предприятия. Для уникальности в пределах БД тип данных int, может еще и сгодится, но вот если брать что-то более глобальное, то четырех миллиардов уникальных значений может и не хватить. Max(int) – это много, но не так много как хотелось бы, проблема в том, что назначая новое автоинкрементное поле, которое по идее должно быть гарантировано уникальным при любых обстоятельствах, приходится думать о других уникальных полях, чтобы ни коим образом диапазоны их идентификаторов не пересеклись, а отсюда и совершенно неестественные ограничения.
Для выхода из подобной ситуации Microsoft предлагает использовать тип данных uniqueidentifier - 16 байтное число, которое, будучи сгенеренным с помощью специальной функции, является гарантировано уникальным при любых обстоятельствах. Вся прелесть такого подхода заключается в том, что такой идентификатор, будучи полученным на одном сервере, заведомо не пересечется с другими подобными же идентификаторами, полученными на других серверах. Уникальный идентификатор получается с помощью функции NewID(). Типичный сценарий работы с таким идентификатором выглядит примерно так:
| DECLARE @PrimaryKey uniqueidentifierBEGINTRAN SET @PrimaryKey = NewID()INSERTINTO MasterTbl (PrimaryKey, <... some fields ...>) VALUES (@PrimaryKey, <... some values ...>) INSERTINTO DetailTbl (ForeignKey, <... some other fields ...>) VALUES (@PrimaryKey, <...some other values ...>) COMMIT |
Для разработчиков под ADO.Net есть еще один удобный повод использовать подобный идентификатор. Поскольку, на самом деле, это обычный GUID, то при добавлении записей в отсоединенный набор данных (Dataset), можно совершенно спокойно получить этот идентификатор на клиенте и быть уверенным, что на сервере такого нет.
Таким образом, использовать обычный автоинкремент удобно только в пределах таблицы, а GUID, во всех остальных случаях. Если же, хотя бы в отдаленной перспективе, предвидится какое-нибудь подобие репликации или синхронизации данных между различными базами или серверами, то лучше в качестве идентификатора сразу использовать GUID. Это серьезно уменьшит количество головной боли.
Производительность
Довольно часто возникает вопрос о производительности этих двух способов. Естественно, что в общем случае работа с identity быстрее, чем с GUID. Но заметно это становится только на больших объемах данных, порядка десятков миллионов записей на таблицу. На таких объемах выигрыш от использования identity составляет от 5 до 20% в зависимости от сложности запросов, но эти данные очень приблизительные и всерьез на них ориентироваться не стоит. Если стоит проблема выбора, то лучше померить на конкретных данных и структуре базы.
Основное замедление при работе с GUID возникает из-за того, что он длиннее. Но вовсе не потому, что четыре байта сравнить быстрее, чем шестнадцать. Дело в том, что, как правило, по идентификатору строится индекс, для более эффективного поиска. Узлы индекса хранятся на диске постранично, каждая страница имеет фиксированную длину. И чем больше ключей влезает на одну страницу, тем меньше обращений к диску приходится делать при поиске какого-либо значения, и, как следствие, тем эффективней поиск, поскольку дисковые операции самые дорогие. Таким образом, эффективность поиска по индексу зависит от размера ключа, а при использовании GUID ключ длиннее.
Timestamp (rowvesion)
Строго говоря, существует еще один тип данных, предназначенный для идентификации, но идентификации несколько другого рода. Тип данных rowversion предназначен для идентификации версии строки в пределах базы данных.
| ПРИМЕЧАНИЕ Вообще можно указывать как timestamp (старое название), так и rowversion, но Microsoft рекомендует использовать rowversion, поскольку, во-первых, это более точно отражает суть этого типа данных, а во вторых, ключевое слово timestamp зарезервировано в стандарте для другого типа. |
Если в таблице имеется поле типа rowversion (оно, как и identity, может быть только одно на таблицу), то значение в этом поле будет автоматически меняться, при изменении любого другого поля в записи. Таким образом, запомнив предыдущее значение, можно определить - менялась запись, или нет, не проверяя всех полей. Для каждой базы SQL сервер ведет отдельный счетчик rowversion. При внесении изменения в любую таблицу со столбцом такого типа, счетчик увеличивается на единицу, после чего новое значение сохраняется в измененной строке. Текущее значение счетчика в базе данных хранится в переменной @@DBTS. Для хранения данных rowversion используется 8 байт, посему этот тип вполне может быть представлен, как varbinary(8) или binary(8).
Номер строки
Просьба подсказать способ вывести номер строки является лидером хит-парада. Этот вопрос по сути своей не корректен и, тем не менее, встречается наиболее часто. Но и вопрошающих тоже можно понять, ведь попросить вывести номер строки вполне естественно. Но дело в том, что в реляционной теории вообще нет такого понятия как «номер строки», в этом смысле записи в таблице абсолютно равноценны. Более того, если задуматься, то становится ясно, что в принципе нет таких задач, которые требовали бы нумерации строк на сервере перед отправкой их клиенту. Нет смысла просить номер у хранилища данных, поскольку эта информация не постоянная и зависит от порядка отображения, а, следовательно, не находится в компетенции хранилища. Клиентскому же приложению, занимающемуся отображением полученной информации, не составляет ни какого труда при получении строк пронумеровать их в требуемом порядке.
Безусловно, в каждом сервере баз данных существует способ, возможно относительно легкий, извернуться и пронумеровать строки нужным образом перед отправкой их клиенту, но подобных решений надо по возможности избегать.
ANSI SQL
Этот способ пронумеровать выводимые записи на сервере по идее должен работать на любых СУБД, минимально удовлетворяющих требованиям стандарта ANSI SQL.
| SELECT (SELECT count(*) FROM NumberingTable WHERE OrderedValue <= X.OrderedValue), X.* FROM NumberingTable X ORDERBY OrderedValue |
Способ этот всем хорош, кроме двух вещей: во-первых, необходимо, чтобы столбец, по которому надо сортировать (OrderedValue) был уникальным, а во вторых, работает эта конструкция ужасно медленно, причем скорость падает с каждой новой записью.
Microsoft SQL Server
Вполне стандартным решением для этого сервера является помещение во временную таблицу с автоинкрементом, первичного ключа выборки, которую необходимо пронумеровать. А затем, результирующая выборка объединяется с временной таблицей и сортируется в порядке возрастания автоинкремента.
| SET NOCOUNT ON DECLARE @tmp TABLE(ID int IDENTITY, OuterID int) INSERTINTO @tmp (OuterID) SELECT [ID] FROM sysobjects ORDERBY [Name] SELECT T.[ID], SO.* FROM sysobjects SO INNERJOIN @tmp T ON SO.[ID] = T.OuterID ORDERBY T.[ID] |
Oracle
Здесь можно отделаться более простым запросом, но тоже не совсем тривиальным. Эта СУБД дает некоторый доступ к своей внутренней информации, и внутри у нее записи пронумерованы. Но проблема в том, что сервер нумерует строки для своих нужд до сортировки, поэтому приходится делать вложенный запрос с сортировкой.
| SELECT RowNum, U.* FROM (SELECT * FROM user_tables ORDER BY tablespace_name) U |
Но еще раз хочу напомнить, что если есть возможность избавить сервер от нумерации, значит надо сервер от нее избавлять. В приложении должно быть что-то сильно не так, если требуется подобная функциональность.
Постраничный вывод
Довольно часто, особенно при построении web-сайтов, приходится сталкиваться с задачей постраничного вывода записей. В некоторых СУБД есть специальные параметры для подобного вывода, а в некоторых все приходится делать самостоятельно. Но в любом случае серверу приходится выполнять примерно один и тот же объем работы. Сначала необходимо выбрать все записи, затем отсортировать их, а затем отправить клиенту нужный диапазон. Очевидно, что выдача диапазона без сортировки смысла не имеет, так как СУБД не гарантирует выдачу записей в каком-либо определенном порядке.
Microsoft SQL Server
Здесь можно придумать довольно много решений и все они будут по-своему хороши.
Во-первых, в данном случае, на удивление эффективным может оказаться применение динамических запросов. При удачном стечении обстоятельств (нужные индексы в нужных местах, и достаточно простые выборки пусть и на большом объеме данных) этот способ является самым быстрым.
| DECLARE @Page int, @PageSize int, @MaxRecord varchar(10), @Count varchar(10) SET @Page = 10 SET @PageSize = 20 SET @MaxRecord = cast((@Page * @PageSize + @PageSize) as varchar(10)) SET @Count = cast(@PageSize as varchar(10)) EXECUTE ('SELECT * FROM (SELECT TOP ' + @Count + ' * FROM (SELECT TOP ' + @MaxRecord + ' * FROM sysobjects ORDER BY name ASC) SO1 ORDER BY name DESC) SO2 ORDER BY name') |
Однако при таком подходе следует быть внимательным, поскольку в случае не оптимально написанного запроса производительность падает довольно резко. Впрочем, на таких объемах, где это будет заметно, к написанию любого запроса надо подходить вдумчиво и аккуратно.
Если же вы испытываете подсознательный страх и неприязнь к динамическим запросам, то есть еще ряд способов. Например, можно сделать практически то же самое, что и приведенный выше запрос, но разложить его по частям, воспользовавшись временной таблицей. Из таблицы (или таблиц), которую нужно отобразить постранично, берется поле, однозначно идентифицирующее каждую запись, и скидывается в нужном порядке во временную табличку с автоинкрементным полем. Причем скидывается не все, а только до последней записи отображаемой страницы. А результирующая выборка делается с объединением с вышеупомянутой временной таблицей, ограничивая диапазон по автоинкрементному полю.
| SET NOCOUNT ON DECLARE @Page int, @PageSize int, @MaxRecord intSET @Page = 10 SET @PageSize = 20 DECLARE @pg TABLE(RowNum intIDENTITY, OuterID int) SET @MaxRecord = @Page*@PageSize + @PageSize SETROWCOUNT @MaxRecord INSERTINTO @pg (OuterID) SELECT ID FROM OriginalTable ORDERBY SortValue ASCSETROWCOUNT @PageSize SELECT O.* FROM OriginalTable O INNERJOIN @pg P ON O.ID = P.OuterID WHERE RowNum > @MaxRecords - @PageSize ORDERBY P.RowNum SETROWCOUNT 0 |
Не составляет никаких проблем написать подобную хранимую процедуру, которая разбивала бы на станицы какую угодно комбинацию таблиц подобным образом.
Ознакомившись с этими методами, может возникнуть совершенно законный вопрос - а нельзя ли реализовать все то же самое, но без динамических запросов и без временных таблиц? Точно то же самое нельзя, поскольку ключевое слово TOP не понимает переменных, а жестко зашивать в запрос номер и размер страницы смысла не имеет. Переменные понимает оператор ROWCOUNT, который делает то же самое, что и TOP, но область действия этого оператора распространяется и на подзапросы, что в данном случае не годится, поэтому и приходится использовать временную таблицу.
Но можно использовать курсоры, и с помощью них осуществлять смещение до нужной записи и производить необходимую выборку.
| SET NOCOUNT ON DECLARE @Page int, @PageSize int, @MinRecord int, @MaxRecord intSET @Page = 10 SET @PageSize = 20 SET @MinRecord = @Page*@PageSize SET @MAXRecord = @Page*@PageSize+@PageSize SET ROWCOUNT @MaxRecordDECLARE @Cursor CURSORSET @Cursor = CURSORSCROLL KEYSET READ_ONLYFORSELECT * FROM OriginalTable ORDERBY SortValue OPEN @Cursor FETCHABSOLUTE @MinRecord FROM @Cursor DECLARE @i int SET @i = 0 WHILE @i < @PageSize BEGINFETCHNEXTFROM @Cursor SET @i = @i + 1 ENDCLOSE @Cursor DEALLOCATE @Cursor SET ROWCOUNT 0 |
Этот способ чуть быстрее, чем предыдущий, но обладает тем недостатком, что возвращает не один набор записей, а каждую запись в отдельном наборе.
Можно так же скомбинировать два последних способа и позиционировать с помощью курсора, а затем считывать во временную таблицу нужное количество записей. Получившийся гибрид будет работать довольно быстро, а в некоторых случаях это самый быстрый вариант, и будет наиболее устойчив к различного рода вольностям в запросе.
Что касается относительной скорости всех методов, то тут можно смело использовать то, к чему душа больше лежит, разница составляет не больше нескольких процентов.
Ограничение первой выборки последней записью отображаемой страницы, позволяет довольно сильно повысить скорость выполнения запроса, так как в подавляющем большинстве случаев дальше второй-третьей страницы пользователи не заглядывают. Для очень больших выборок, критичных ко времени обращения к последним страницам, можно придумать хитрую процедуру, которая умела бы различать начальные и конечные страницы, и к последним применять обратную сортировку при выборке. Таким образом, к первым и последним страницам был бы наиболее быстрый доступ.
Oracle
В Оракле проблема постраничного вывода решается несколько проще. Стандартный способ, подходящий для подавляющего большинства задач выглядит примерно так:
| SELECT * FROM (SELECT A.*, RowNum R FROM (SELECT * FROM user_tables ORDERBY table_name) A WHERE RowNum < :MaxRecord) WHERE R >= :MinRecord |
Однако при большом желании, так же можно придумать хитрую процедуру, которая по-разному обрабатывала бы начальные и конечные станицы большой выборки.
Yukon
В новой версии Microsoft SQL Server специальных ключевых слов, для подобной функциональности не добавилось, но, тем не менее, постраничную выборку можно немного упростить. В этой версии ключевое слово TOP стало понимать переменные, и даже запросы, и постраничный вывод можно организовать примерно так:
| SELECT * FROM (SELECTTOP (@PageSize) * FROM (SELECTTOP (@Page * @PageSize + @PageSize) * FROM sys.objects ORDERBY name ASC) SO1 ORDERBY name DESC) SO2 ORDERBY name |
Скорости это не добавит, так как сервер все равно выполняет примерно одну и ту же работу, но количество нажатий на клавиатуру несколько уменьшится, что, возможно, продлит срок ее службы. Ну и код выглядит компактнее, что конечно приятно.
Упростить постраничный вывод вряд ли возможно. Существуют СУБД, в которых введен специальный синтаксис для вывода данных постранично, но это не более чем syntactic sugar, так как производятся те же действия, что и в примерах выше, просто часть реализации остается за кадром.
Эта статья опубликована в журнале RSDN Magazine #1-2004. Информацию о журнале можно найти здесьrsdn.org
SQL AUTO ИНКРЕМЕНТ поле
Автоинкрементная позволяет уникальное число, генерируемое, когда новая запись вставляется в таблицу.
AUTO ИНКРЕМЕНТ поле
Очень часто мы хотели бы значение поля первичного ключа, которая будет создана автоматически каждый раз, когда новая запись вставляется.
Мы хотели бы создать поле Автоинкрементная в таблице.
Синтаксис для MySQL
Следующий SQL заявление определяет "ID" столбец , чтобы быть первичным ключом в автоприращением "Persons" таблицы:
CREATE TABLE Persons ( ID int NOT NULL AUTO_INCREMENT, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255), PRIMARY KEY (ID) )
MySQL использует ключевое слово AUTO_INCREMENT, чтобы выполнить функцию автоматического приращения.
По умолчанию начальное значение для AUTO_INCREMENT равно 1, и она будет увеличиваться на 1 для каждой новой записи.
Для того, чтобы последовательность AUTO_INCREMENT начать с другого значения, используйте следующую инструкцию SQL:
ALTER TABLE Persons AUTO_INCREMENT=100
Для того, чтобы вставить новую запись в "Persons" таблицы, мы не должны указать значение для "ID" столбце (уникальное значение будет добавлено автоматически):
INSERT INTO Persons (FirstName,LastName) VALUES ('Lars','Monsen')
SQL выше утверждение будет вставить новую запись в "Persons" таблицы. "ID" столбец будет присвоено уникальное значение. "FirstName" столбец должен быть установлен на "Lars" и "LastName" столбец должен быть установлен на "Monsen" .
Синтаксис для SQL Server
Следующий SQL заявление определяет "ID" столбец , чтобы быть первичным ключом в автоприращением "Persons" таблицы:
CREATE TABLE Persons ( ID int IDENTITY(1,1) PRIMARY KEY, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255) )
MS SQL Server использует Идентичность ключевое слово, чтобы выполнить функцию автоматического приращения.
В приведенном выше примере начальное значение для Идентичность 1, и она будет увеличиваться на 1 для каждой новой записи.
Совет: Для того, чтобы указать , что "ID" столбец должен начинаться при значении 10 и приращении на 5, изменить его на тождестве (10,5).
Для того, чтобы вставить новую запись в "Persons" таблицы, мы не должны указать значение для "ID" столбце (уникальное значение будет добавлено автоматически):
INSERT INTO Persons (FirstName,LastName) VALUES ('Lars','Monsen')
SQL выше утверждение будет вставить новую запись в "Persons" таблицы. "ID" столбец будет присвоено уникальное значение. "FirstName" столбец должен быть установлен на "Lars" и "LastName" столбец должен быть установлен на "Monsen" .
Синтаксис для доступа
Следующий SQL заявление определяет "ID" столбец , чтобы быть первичным ключом в автоприращением "Persons" таблицы:
CREATE TABLE Persons ( ID Integer PRIMARY KEY AUTOINCREMENT, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255) )
MS Access использует AUTOINCREMENT ключевое слово, чтобы выполнить функцию автоматического приращения.
По умолчанию начальное значение для Autoincrement равно 1, и она будет увеличиваться на 1 для каждой новой записи.
Совет: Для того, чтобы указать , что "ID" столбец должен начинаться при значении 10 и приращении на 5, изменить автоинкрементного к автоинкрементация (10,5).
Для того, чтобы вставить новую запись в "Persons" таблицы, мы не должны указать значение для "ID" столбце (уникальное значение будет добавлено автоматически):
INSERT INTO Persons (FirstName,LastName) VALUES ('Lars','Monsen')
SQL выше утверждение будет вставить новую запись в "Persons" таблицы. "P_Id" колонка будет присвоено уникальное значение. "FirstName" столбец должен быть установлен на "Lars" и "LastName" столбец должен быть установлен на "Monsen" .
Синтаксис для Oracle
В Oracle код немного сложнее.
Вы должны создать поле Автоинкрементная с объектом последовательности (этот объект генерирует последовательность чисел).
Используйте следующий синтаксис CREATE SEQUENCE:
CREATE SEQUENCE seq_person MINVALUE 1 START WITH 1 INCREMENT BY 1 CACHE 10
Приведенный выше код создает объект последовательности под названием seq_person, который начинается с 1 и будет увеличиваться на 1. Он также будет кэшировать до 10 значений для повышения производительности. Опция кэша определяет, сколько значений последовательности будут сохранены в памяти для быстрого доступа.
Для того, чтобы вставить новую запись в "Persons" таблицы, мы будем использовать функцию NEXTVAL (эта функция возвращает следующее значение из последовательности seq_person):
INSERT INTO Persons (ID,FirstName,LastName) VALUES (seq_person.nextval,'Lars','Monsen')
SQL выше утверждение будет вставить новую запись в "Persons" таблицы. "ID" столбец будет присвоен следующий номер из последовательности seq_person. "FirstName" столбец должен быть установлен на "Lars" и "LastName" столбец должен быть установлен на "Monsen" .
www.w3bai.com