Подключение к ошибке DB PostgreSQL. C подключение к postgresql
Строка подключения к СУБД PostgreSQL
Как в 1С обратиться к внешнему источнику данных, который таится в недрах СУБД? Ответ на этот вопрос начинается с подключения в 1С к этому источнику данных через интерфейс COM-объекта. В этой статье рассмотрим подключение с помощью интерфейса ADODB. Свои попытки мы будем осуществлять с СУБД PostgreSQL.
Строка подключения
Подключение клиента 1С к серверу любой СУБД осуществляется при помощи строки подключения. У каждой СУБД они немного отличаются.
Рассмотрим, какие же параметры содержит в себе строка подключения:
| Параметр | Описание параметра | Значение параметра |
| DRIVER | Драйвер СУБД ODBC | PostgreSQL Unicode |
| Data Source | Источник данных | PostgreSQL35W |
| SERVER | Имя сервера СУБД | srv1 |
| PORT | Номер порта сервера СУБД | |
| DATABASE | Имя БД | parser |
| UID | Имя пользователя СУБД | sauser |
| PWD | Пароль пользователя СУБД | ******** |
С этими параметрами строка подключения будет выглядеть так:
DRIVER={PostgreSQL Unicode}; Data Source=PostgreSQL35W; SERVER=srv1; PORT=5432; DATABASE=parser; UID=sauser; PWD=qwerty
Настройки сервера СУБД
Перед тем, как соединяться с БД, необходимо настроить сервер СУБД PostgreSQL. Это делается так:
1. Идём в меню Пуск — Панель управления — Система и безопасность – Администрирование.
2. Выбираем пункт «Источники данных ODBC» (64- или 32-разрядная версия в зависимости от разрядности архитектуры клиента и сервера).
3. На вкладке «Драйверы» должен присутствовать «PostgreSQL ODBC Driver(UNICODE)» или «PostgreSQL ODBC Driver(ANSI)».
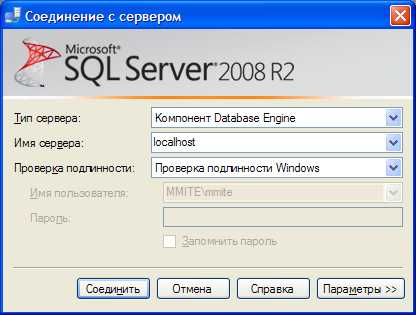
4. На вкладке «Системный DNS» должен присутствовать источник данных «PostgreSQL35W». Если такого источника данных нет, его нужно добавить, прописав: имя используемой БД, сервер, имя пользователя и пароль. Если СУБД PostgreSQL установлена на этом же компьютере, то сервер должен иметь имя «localhost».
5. Чтобы протестировать созданное соединение, в окне источника данных нажимаем кнопку «Test». После удачного тестирования появляется окно.
6. Если всё прошло удачно, сохраняем результат, нажимаем кнопку «Save».
Функции подключения 1С
Теперь для того, чтобы подключить 1С Предприятие к СУБД PostgreSQL, можно использовать следующие готовые функции:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | Функция ОткрытьПодключение(СтрокаКоннекта, ТаймАут) Экспорт Соединение = Новый COMОбъект("ADODB.Connection"); Соединение.ConnectionTimeOut = Число(ТаймАут); Попытка Соединение.Open(СтрокаКоннекта); Исключение Сообщить(ОписаниеОшибки(), СтатусСообщения.ОченьВажное); Возврат Неопределено; КонецПопытки; Возврат Соединение; КонецФункции Процедура ЗакрытьПодключение(Соединение) Экспорт Попытка Если Соединение <> Неопределено Тогда Соединение.Close(); КонецЕсли; Исключение Сообщить(ОписаниеОшибки(), СтатусСообщения.ОченьВажное); КонецПопытки; Соединение = Неопределено; КонецПроцедуры; |
Как обратиться к внешней СУБД? Пишем в модуле 1С такую конструкцию:
| 1 2 3 4 | СтрокаСоединения = "DRIVER={PostgreSQL Unicode}; Data Source=PostgreSQL35W; SERVER=srv1; PORT=5432; DATABASE=parser; UID=sauser; PWD=qwerty"; Соединение = ОткрытьПодключение(СтрокаСоединения, 120); // Обращение к БД ЗакрытьПодключение(Соединение); |
Обработку для тестирования соединения с БД можно скачать ниже по ссылке. Обработка сделана как для управляемых форм, так и для обычного интерфейса 1С.
Нравится статья? Подпишитесь прямо сейчас и получайте обновления на свой E-Mail:
Мой мир
Вконтакте
Одноклассники
Google+
Похожее
Распечатать статьюlife1c.ru
PostgreSQL : Документация: 10: 19.3. Подключения и аутентификация : Компания Postgres Professional
authentication_timeout (integer)Разрешает подключения SSL. Прежде чем его использовать, прочитайте Раздел 18.9. Этот параметр можно задать только в postgresql.conf или в командной строке при запуске сервера. Значение по умолчанию — off.
ssl_ca_file (string)Задаёт имя файла, содержащего сертификаты центров сертификации (ЦС) для SSL-сервера. При указании относительного пути он рассматривается от каталога данных. Этот параметр можно задать только в postgresql.conf или в командной строке при запуске сервера. По умолчанию этот параметр пуст, что означает, что файл сертификатов ЦС не загружается и проверка клиентских сертификатов не производится.
В предыдущих выпусках PostgreSQL это имя было неизменяемым — root.crt.
ssl_cert_file (string)Задаёт имя файла, содержащего сертификат этого SSL-сервера. При указании относительного пути он рассматривается от каталога данных. Этот параметр можно задать только в postgresql.conf или в командной строке при запуске сервера. Значение по умолчанию — server.crt.
Задаёт имя файла, содержащего список отзыва сертификатов (CRL, Certificate Revocation List) для SSL-сервера. При указании относительного пути он рассматривается от каталога данных. Этот параметр можно задать только в postgresql.conf или в командной строке при запуске сервера. По умолчанию этот параметр пуст, что означает, что файл CRL не загружается.
В предыдущих выпусках PostgreSQL имя этого файла было неизменяемым — root.crl.
ssl_key_file (string)Задаёт имя файла, содержащего закрытый ключ SSL-сервера. Этот параметр можно задать только в postgresql.conf или в командной строке при запуске сервера. Значение по умолчанию — server.key.
ssl_ciphers (string)Задаёт список наборов шифров SSL, которые могут применяться для защиты соединений. Синтаксис этого параметра и список поддерживаемых значений можно найти на странице ciphers руководства по OpenSSL. Этот параметр можно задать только в postgresql.conf или в командной строке при запуске сервера. Значение по умолчанию — HIGH:MEDIUM:+3DES:!aNULL. Обычно оно вполне приемлемо при отсутствии особых требований по безопасности.
Объяснение значения по умолчанию:
HIGHНаборы шифров, в которых используются шифры из группы высокого уровня (HIGH), (например: AES, Camellia, 3DES)
MEDIUMНаборы шифров, в которых используются шифры из группы среднего уровня (MEDIUM) (например, RC4, SEED)
+3DESПорядок шифров для группы HIGH по умолчанию в OpenSSL определён некорректно. В нём 3DES оказывается выше AES128, что неправильно, так как он считается менее безопасным, чем AES128, и работает гораздо медленнее. Включение +3DES меняет этот порядок, чтобы данный алгоритм следовал после всех шифров групп HIGH и MEDIUM.
!aNULLОтключает наборы анонимных шифров, не требующие проверки подлинности. Такие наборы уязвимы для атак с посредником, поэтому использовать их не следует.
Конкретные наборы шифров и их свойства очень различаются от версии к версии OpenSSL. Чтобы получить фактическую информацию о них для текущей установленной версии OpenSSL, выполните команду openssl ciphers -v 'HIGH:MEDIUM:+3DES:!aNULL'. Учтите, что этот список фильтруется во время выполнения, в зависимости от типа ключа сервера.
Определяет, должны ли шифры SSL сервера предпочитаться клиентским. Этот параметр можно задать только в postgresql.conf или в командной строке при запуске сервера. Значение по умолчанию — true.
В старых версиях PostgreSQL этот параметр отсутствовал и предпочтение отдавалось выбору клиента. Введён этот параметр в основном для обеспечения совместимости с этими версиями. Вообще же обычно лучше использовать конфигурацию сервера, так как в конфигурации на стороне клиента более вероятны ошибки.
ssl_ecdh_curve (string)Задаёт имя кривой для использования при обмене ключами ECDH. Эту кривую должны поддерживать все подключающиеся клиенты. Это не обязательно должна быть кривая, с которой был получен ключ сервера. Этот параметр можно задать только в postgresql.conf или в командной строке при запуске сервера. Значение по умолчанию — prime256v1.
Наиболее распространённые кривые в OpenSSL — prime256v1 (NIST P-256), secp384r1 (NIST P-384), secp521r1 (NIST P-521). Полный список доступных кривых можно получить командой openssl ecparam -list_curves. Однако не все из них пригодны для TLS.
Когда в CREATE ROLE или ALTER ROLE задаётся пароль, этот параметр определяет, каким алгоритмом его шифровать. Значение по умолчанию — md5 (пароль сохраняется в виде хеша MD5), также в качестве псевдонима md5 принимается значение on. Значение scram-sha-256 указывает, что пароль будет шифроваться алгоритмом SCRAM-SHA-256.
Учтите, что старые клиенты могут не поддерживать механизм проверки подлинности SCRAM и поэтому не будут работать с паролями, зашифрованными алгоритмом SCRAM-SHA-256. За подробностями обратитесь к Подразделу 20.3.2.
ssl_dh_params_file (string)Задаёт имя файла с параметрами алгоритма Диффи-Хеллмана, применяемого для так называемого эфемерного семейства DH шифров SSL. По умолчанию значение пустое, то есть используются стандартные параметры DH, заданные при компиляции. Использование нестандартных параметров DH защищает от атаки, рассчитанной на взлом хорошо известных встроенных параметров DH. Создать собственный файл с параметрами DH можно, выполнив команду openssl dhparam -out dhparams.pem 2048.
Задать этот параметр можно только в postgresql.conf или в командной строке при запуске сервера.
Задаёт размещение файла ключей для сервера Kerberos. За подробностями обратитесь к Подразделу 20.3.3. Задать этот параметр можно только в postgresql.conf или в командной строке при запуске сервера.
krb_caseins_users (boolean)Определяет, должны ли имена пользователей GSSAPI обрабатываться без учёта регистра. По умолчанию значение этого параметра — off (регистр учитывается). Задать этот параметр можно только в postgresql.conf или в командной строке при запуске сервера.
db_user_namespace (boolean)Этот параметр позволяет относить имена пользователей к базам данных. По умолчанию он имеет значение off (выключен). Задать этот параметр можно только в postgresql.conf или в командной строке при запуске сервера.
Если он включён, имена создаваемых пользователей должны иметь вид имя_пользователя@база_данных. Когда подключающийся клиент передаёт имя_пользователя, к этому имени добавляется @ с именем базы данных, и сервер идентифицирует пользователя по этому полному имени. Заметьте, что для создания пользователя с именем, содержащим @, в среде SQL потребуется заключить это имя в кавычки.
Когда этот параметр включён, он не мешает создавать и использовать обычных глобальных пользователей. Чтобы подключиться с таким именем пользователя, достаточно добавить к имени @, например так: joe@. Получив такое имя, сервер отбросит @, и будет идентифицировать пользователя по начальному имени.
Параметр db_user_namespace порождает расхождение между именами пользователей на стороне сервера и клиента. Но проверки подлинности всегда выполняются с именем с точки зрения сервера, так что, настраивая аутентификацию, следует указывать серверное представление имени, а не клиентское. Так как метод аутентификации md5 подмешивает имя пользователя в качестве соли и на стороне сервера, и на стороне клиента, при включённом параметре db_user_namespace использовать md5 невозможно.
Примечание
Эта возможность предлагается в качестве временной меры, пока не будет найдено полноценное решение. Тогда этот параметр будет ликвидирован.
postgrespro.ru
c# - Подключение к ошибке DB PostgreSQL
В настоящее время я работаю над проектом.NET.NET С#. он использует внешнюю программу, которая принимает аргумент, когда я его создаю и запускаю. Внешняя программа предназначена для индексации структурированного или неструктурированного источника данных.
Проект С# - это простая.dll, которая переопределяет некоторые внешние программные методы. В части инициализации я запрашиваю подключение к моей базе данных postgreSQL, чтобы вернуть уникальный идентификатор.
ПРЕДУПРЕЖДЕНИЕ. У индексатора и моей БД нет ссылки, индексир может индексировать папку с файлами.xls или mysql DB. Мой PostgreSQL предназначен только для того, чтобы принести уникальный идентификатор и хранить некоторые важные сведения
Моя проблема заключается в том, что я запускаю в качестве внешней программы DBConnector, который является 32-битным индексом, все идет хорошо.
Если я запускаю AlfrescoConnector, который является 64-битным индексом, я не могу открыть свою базу данных postgreSQL.
Я вставил x86 и x64 тип разъема, но я не знаю, возникает ли проблема.
Я работаю над Visual 2012, мой отладчик настроен на создание x86-совместимой программы (изменение ее на "любой процессор" или "x64" не решает проблему)
Объектом db, который я использую, является DbClient, который является конкретным методом, который вы не найдете в Интернете, потому что он исходит из ссылки на внешнюю программу, но он работает как классический DbConnector.
Мой объект DbClient выглядит следующим образом:
- dbClient = {Sinequa.Common.DbClient}
- _CurrentTransaction = null
- ConnectionString = "Server = localhost; Порт = 5444; Идентификатор пользователя = USERSAMPLE; База данных = DBSAMPLE; Пароль = PWDSAMPLE;"
- DbCn = null
- DbCnSubSelect = null
- DbFactory = null
- DbIsolationLevel = Unspecified
- DefaultCommandBehavior = SequentialAccess
- Двигатель = Postgres
- Ошибка = 0
- ErrorText = null
- LastRowAffected = 0
- LOBFetchSize = 0
- Provider = "Npgsql"
- RefreshCount = 0
- RefreshCurrent = 0
- Schema = null
Ошибка возникает, когда я делаю myDbClient.Open() с Alfresco one
Какие-либо предложения? Нужна более подробная информация? Я готов решить эту мучительную ошибку с тобой, мои товарищи!
qaru.site
Подключение к базе данных PostgreSQL
Подключение к базе данных PostgreSQL
Январь 1st, 2013 admin
Подключение к базе данных PostgreSQL из консоли.
В моей практике, в основном, было использование MySQL серверов. Здесь я опишу основные моменты работы с PostgreSQL.
Для подключения к БД PostgreSQL набираем:
Получить список баз данных на сервере после входа можно командой:
Получить список таблиц в текущей базе данных PostgreSQL:
Конфигурационные файлы PostgreSQL находятся в:
| # mcedit /var/lib/postgresql/8.4/data/postgresql.conf # mcedit /var/lib/postgresql/8.4/data/pg_hba.conf |
Можем удалить все таблицы в базе данных. Подготавливаем файл для выполнения в консоли:
| # psql -U postgresql-user -t -d postgresql-db -c \ "SELECT 'DROP TABLE ' || n.nspname || '.' || c.relname || ' CASCADE;' \ FROM pg_catalog.pg_class AS c LEFT JOIN pg_catalog.pg_namespace AS n \ ON n.oid = c.relnamespace WHERE relkind = 'r' AND n.nspname NOT IN \ ('pg_catalog', 'pg_toast') AND pg_catalog.pg_table_is_visible(c.oid)" \ > /tmp/droptables |
Выполняем удаление всех таблиц:
| # psql -U postgresql-user -d postgresql-db -f /tmp/droptables |
xn----ptbqdfpl.xn--p1ai
Подключение таблиц PostgreSQL к базе данных MS Access | Access | Статьи | Программирование Realcoding.Net
При создании многопользовательского приложения важно сделать процесс его распространения по рабочим местам как можно проще. Важная часть этой проблемы - обеспечение программного подключения таблиц к источнику данных. Если данные хранятся в базе MS Access, то всё просто, но при использовании любого SQL-сервера задача заметно усложняется.
Основная проблема заключается в том, что для присоединения таблицы или представления с сервера требуется установить ODBC-драйвер и зарегистрировать в системе так называемое имя источника данных (Data Source Name, DSN), которое служит для хранения специфической информации о конкретном соединении, обеспечиваемом драйвером. Если приложению требуются соединения с различными серверами, базами данных или просто отличающиеся какими-либо параметрами, то потребуется создать несколько DSN.
Вручную сделать всё это очень просто. Достаточно запустить программу установки ODBC драйвера, а потом создать все нужные DSN с помощью Администратора источников данных ODBC, который находится в панели управления Windows. Проблема в том, что когда пользователей много, данная нехитрая процедура превращается в целое мероприятие. Как же автоматизировать этот процесс? Ну, с установкой драйвера всё достаточно просто: надо скопировать на компьютер пользователя необходимые файлы и добавить ключи в реестр Windows. Какие именно - зависит от самого драйвера. Это, конечно, может вызвать затруднения, однако, в крайнем случае, установить драйвер можно вручную один раз, а обновление версий проводить автоматически, как правило, заменой единственного файла динамической библиотеки.
Создать DSN ещё проще. В MS Access есть специальная функция для регистрации нового источника данных:
DBEngine.RegisterDatabase <Имя источника данных>, _ <Название ODBC драйвера>, _ <Выводить или нет окно диалога драйвера ODBC>, _ <Список атрибутов> Этим возможности Access и ограничиваются. Получить список источников данных и, тем более, значения отдельных параметров каждого источника с помощью встроенных средств MS Access невозможно. Однако не беда, процедуру RegisterDatabase можно запускать при каждом старте программы и, если Вы захотите установить другие значения параметров соединения, они просто будут перезаписаны поверх старых.Дальше, надо собственно подключить внешние таблицы и представления к базе данных Вашего приложения. Тут есть два пути: первый - простой, но менее гибкий и, возможно, более интерактивный. Он предполагает использование команды DoCmd.TransferDatabase с типом преобразования acLink. Подробное описание приводится в справочной системе MS Access.
Второй путь сложнее, но позволяет полностью программно контролировать присоединение таблицы и заключается в создании нового объекта TableDef. Рассмотрим этот способ подробнее. Перед тем, как подключать таблицу, проверим нашу базу данных на предмет существования объекта с таким же именем, например, этой функцией:
Function IsTableExist(TableName As String) As Long ' Функция возвращает следующие коды: ' 0 - Ни таблицы ни запроса с указанным именем не существует. ' 1 - Существует локальная таблица с указанным именем. ' 2 - Существует присоединённая таблица с указанным именем. ' 3 - Существует запрос с указанным именем. On Error Resume Next Dim db As Database Dim td As TableDef Dim qd As QueryDef IsTableExist = 0 err.Clear Set db = CurrentDb Set td = db.TableDefs(TableName) If err.Number = 0 Then If td.Connect = "" Then 'Таблица локальная IsTableExist = 1 Else 'Таблица присоединенная IsTableExist = 2 End If Set td = Nothing Set db = Nothing Exit Function End If err.Clear Set qd = db.QueryDefs(TableName) If err.Number = 0 Then IsTableExist = 3 'Запрос Set qd = Nothing Set db = Nothing End Function Если эта функция показала, что существует локальная таблица или запрос с таким же именем, как у таблицы, которую мы хотим подключить, то прекращаем все дальнейшие действия. Если же существует присоединённая таблица, удалим её и продолжим, как и в случае отсутствия объекта с указанным именем.Теперь наша задача - создать объект TableDef таким образом, чтобы он оказался присоединённой таблицей, полностью пригодной для любых операций с данными. Сначала создадим сам объект TableDef:
Set NewTableDef = CurrentDB.CreateTableDef("Имя таблицы в БД MS Access") NewTableDef.Connect = "Строка подключения" NewTableDef.SourceTableName = "Имя таблицы или представления на сервере" Как видите, нет необходимости специально указывать, что мы хотим создать именно присоединённую таблицу ODBC. Access сам определяет это анализируя строку подключения. О том, как её правильно сформировать - чуть позже. Теперь добавим только что созданное определение таблицы в коллекцию TableDefs: CurrentDB.TableDefs.Append NewTableDef И в конце поможем Access'у определить первичный ключ, если он сам его не распознал, что является нормальным явлением при подключении представлений (VIEW): CurrentDB.Execute "CREATE UNIQUE INDEX PrimaryKey ON " & _ "Имя таблицы в БД MS Access" & "(" & _ "Список полей первичного ключа" & ")" Самое сложное здесь - составить строку подключения. В начале обязательно нужно указать "ODBC;", затем - имя источника данных ("ODBC;DSN=<Имя источника данных>;..."), имя пользователя ("...;UID=<Логин>;...") и пароль ("...;PWD=<Пароль>;...") например: "ODBC;DSN=PostgreSQL Test;UID=Postgres;PWD=secret;" Далее, при необходимости, можно указать имя базы данных и другие параметры, в том числе, специфичные для используемого ODBC драйвера. Порядок следования опций не имеет особого значения, так как все они различаются по именам (DSN, UID, DB). В качестве разделителя используется точка с запятой (;). Например: NewTableDef.Connect = "ODBC;DSN=PG_Sample;DATABASE=sample;SERVER=test;" & _ "UID=Postgres;PWD=;PORT=5432;""На этом можно было бы закончить, но нельзя не упомянуть, что у некоторых ODBC драйверов есть одна замечательная особенность: они позволяют подключать таблицы вообще без создания DSN. В их числе драйверы для MS SQL Server 7.0 и PostgreSQL. Для этого надо просто вместо параметра DSN указать параметр DRIVER и имя драйвера, заключенное в фигурные скобки. Конечно, в таком случае потребуется указать все необходимые драйверу опции. Например:
NewTableDef.Connect = "ODBC;DRIVER={PostgreSQL};DATABASE=sample;SERVER=test;" & _ "UID=Postgres;PWD=;PORT=5432;A6=;A7=100;" & _ "C2=dd_;CX=188373ab;A8=4096;B0=254;B1=8190;BI=8;" Опций может быть довольно много и это вызывает очень серьёзную проблему: длина строки подключения не может превышать приблизительно 270 символов. Разработчики драйвера PostgreSQL это понимают и пытаются найти выход путём кодирования некоторых опций. Параметр CX и является таким кодом. Формируется он так: первые два байта содержат количество реально значимых битов в последующем числе (в шестнадцатиричном формате). Например, 18 означает, что используются 24 бита которые представляют следующие опции драйвера: -- Младший бит -- LF <-> CR/LF conversion Updatable Cursors Disallow Premature Recognize Unique Index PROTOCOL 6.3 PROTOCOL 7.X,6.4 Unknown Sizes(Don't know) Unknown Sizes(Maximum) Disable Genetic Optimizer KSQO CommLog MyLog Parse Statements Cancel As FreeStmt Use Declare/Fetch Read Only Text As LongVarChar Unknowns As LongVarChar Bools As Char Row Versioning Show System Tables Oid Options(Show Column) Oid Options(Fake Index) True is -1 -- Старший бит -- Некоторые параметры невозможно закодировать таким образом и для их именования продолжают использовать буквоцифровые сокращения: Connect Settings A6 Cache Size A7 Socket A8 Max Varchar B0 Max LongVarChar B1 SysTable Prefixes C2 Int8 As BIПример, который я сделал для Access'97, можно взять здесь. Он основан на подходе, описанном в заметке «Программное подключение таблиц из внешней базы данных MS Access», но содержит дополнительную таблицу, в которой хранится информация, необходимая для подключения к серверу. Так как сам подход достаточно универсален, пример годится для подключения не только к серверу PostgreSQL, но и к любому другому, возможно, с какими-нибудь незначительными доработками.
Строку подключения можно легко получить, присоединив таблицу вручную, а затем скопировав всё содержимое свойства «Описание» (кроме тега table=...) из свойств таблицы, открытой в режиме конструктора. Для сервера PostgreSQL можно воспользоваться надстройкой, которую я создал специально для формирования строк коннекта и минимального администрирования сервера.
www.realcoding.net
Подключение к PostgreSQL
Вопрос: Выбор сервера под PostgreSQL
Итак, наступл тот момент, когда было принято решение купить новую хост-машину. На хост-машину будем ставить виртуалку postgresql. На сейчас имеем один сервер БД и 130Гб данных, причём 100Гб - это одна таблица, к которой будет в будущем очень много длительных запросов (все данные на SSD 256Гб). Эта же таблица может однократно вырасти до 2-3Тб. Нагрузки на сервер - короткие частые сессии. Управляет ими PgBouncer. Запись производится редко, но много, что сильно нагружает файловую систему. Если верить Zabbix, то "iowait time">50%. На какие параметры обратить внимание при выборе сервера?Есть ли смысл покупать SSD на несколько терабайт или лучше собрать RAID 01 (или 10) из десятка HDD без потери производительности?На сколько я понял, PostgreSQL под одно подключение выделяет одно ядро. Если у меня 6 ядерный проц сейчас, то не желательно ставить количество возможных подключений больше 6? По поводу ОЗУ тоже всё неоднозначно. Одни советуют ставить work_mem и shared_buffer побольше, другие говорят о том, что не нужно ставить больше определённого значения. Интересна Ваша мысль. Бюджет - $3k-$5k, но нужна адекватная аргументация для менеджмента.Буду благодарен за любые советы.
Ответ:| Бюджет - $3k-$5k, но нужна адекватная аргументация для менеджмента. |
явно речь идет не о брендовом сервере (он в эти деньги скорее всего не впишется), но и даже самосборный сервер, IMHO выбора будет не много
пара серверных SSD (если в RAID-1) + взять пару десктопных винтов для хранения архивов/дистрибутивов/порнухи (куда же на сервере без нее?)... деньги и закончатся
по личному опыту, примерно 15 летней давности, я сервер выбирал так:корпус ))) + мамапамять RAMну и остальное, сколько осталось денег )))
в вашем случае, наверное и сложнее и проще. Т.к. фиг его знает, в какие серверные мамы, какие высокопроизводительные серверные (!!!) SSD можно поставить. Я бы определился с SSD, какой хочется, потом посмотрел на платформы, куда его можно поставить... думаю выбор будет не сильно большой.
ну и RAM по максимуму, плюс тюнинг PostgreSQL
Чисто теоретически, если RAM много и настройки нормальные, то кто кэширует запись на диск сам PostgreSQL или дисковая система (RAID контроллер) - разницы быть не должно. Если RAM достаточна, что бы сгладить пики "запись производится редко, но много", то wait из-за обращения к дискам быть не должно. IMHO & AFAIK
Но это теоретически. Практически, баги и непонятностей в софте/доках дофига. Не все работает так, как должно было бы работать теоретически.
forundex.ru
неожиданно не работает подключение к PostgreSQL c внешнего сервера
Вопрос: Выбор сервера под PostgreSQL
Итак, наступл тот момент, когда было принято решение купить новую хост-машину. На хост-машину будем ставить виртуалку postgresql. На сейчас имеем один сервер БД и 130Гб данных, причём 100Гб - это одна таблица, к которой будет в будущем очень много длительных запросов (все данные на SSD 256Гб). Эта же таблица может однократно вырасти до 2-3Тб. Нагрузки на сервер - короткие частые сессии. Управляет ими PgBouncer. Запись производится редко, но много, что сильно нагружает файловую систему. Если верить Zabbix, то "iowait time">50%. На какие параметры обратить внимание при выборе сервера?Есть ли смысл покупать SSD на несколько терабайт или лучше собрать RAID 01 (или 10) из десятка HDD без потери производительности?На сколько я понял, PostgreSQL под одно подключение выделяет одно ядро. Если у меня 6 ядерный проц сейчас, то не желательно ставить количество возможных подключений больше 6? По поводу ОЗУ тоже всё неоднозначно. Одни советуют ставить work_mem и shared_buffer побольше, другие говорят о том, что не нужно ставить больше определённого значения. Интересна Ваша мысль. Бюджет - $3k-$5k, но нужна адекватная аргументация для менеджмента.Буду благодарен за любые советы.
Ответ:| Бюджет - $3k-$5k, но нужна адекватная аргументация для менеджмента. |
явно речь идет не о брендовом сервере (он в эти деньги скорее всего не впишется), но и даже самосборный сервер, IMHO выбора будет не много
пара серверных SSD (если в RAID-1) + взять пару десктопных винтов для хранения архивов/дистрибутивов/порнухи (куда же на сервере без нее?)... деньги и закончатся
по личному опыту, примерно 15 летней давности, я сервер выбирал так:корпус ))) + мамапамять RAMну и остальное, сколько осталось денег )))
в вашем случае, наверное и сложнее и проще. Т.к. фиг его знает, в какие серверные мамы, какие высокопроизводительные серверные (!!!) SSD можно поставить. Я бы определился с SSD, какой хочется, потом посмотрел на платформы, куда его можно поставить... думаю выбор будет не сильно большой.
ну и RAM по максимуму, плюс тюнинг PostgreSQL
Чисто теоретически, если RAM много и настройки нормальные, то кто кэширует запись на диск сам PostgreSQL или дисковая система (RAID контроллер) - разницы быть не должно. Если RAM достаточна, что бы сгладить пики "запись производится редко, но много", то wait из-за обращения к дискам быть не должно. IMHO & AFAIK
Но это теоретически. Практически, баги и непонятностей в софте/доках дофига. Не все работает так, как должно было бы работать теоретически.
forundex.ru