24.2. Резервное копирование на уровне файлов. Бэкап базы данных postgresql
Резервное копирование и обслуживание баз данных PostgreSQL для 1С:Предприятие
Создание временного хранилища
Создадим отдельный диск в виртуальной машине ESXi 6.5 для временного хранения архивных копий.
Для отображения подключенных дисков выполним команду:
fdisk -l | grep "Disk /dev/sd"Подключенный диск имеет название sdf.
Разметим пространство. В качестве файловой системы выберем ext4:
mkfs.ext4 /dev/sdfСоздадим точку монтирования — каталог /backup
mkdir /backupМонтируем созданный ранее диск в каталог /backup:
mount /dev/sdf /backupДля автоматического монтирования диска при загрузке системы выполним команду (редактор mcedit входит в состав файлового менеджера MC):
mcedit /etc/fstabв открывшемся файле добавим строчки:
/dev/sdf /backup ext4 defaults 1 2
Резервное копирование
Так как доступ к серверу имеет только администратор, то для упрощения разрешим подключаться к серверу PostgreSQL локально без авторизации.
в открывшемся файле изменим строки:
local all all peer на local all all trust
Для принятия изменений перезагрузим сервер СУБД:
systemctl restart postgresql-9.6Для создания резервной копии создадим скрипт, в котором воспользуемся утилитой pg_dump, позволяющая создать дамп для указанной БД.
Создание дампа происходит без блокирования таблиц и представляет снимок БД на момент выполнения команды.
Дамп БД будем архивировать с помощью pigz, т. к. он использует все ядра процессора.
Установим архиватор pigz:
yum -y install pigzПеред архивированием можно посмотреть список БД на сервере и для справки уточнить наименование БД и её кодировку:
psql -U postgres -lДля хранения архивов в «облаке» воспользуемся сервисом Яндекс.Диск.
Установим консольный клиент:
В ходе установки укажем: будем или нет использовать прокси сервер, логин и пароль для авторизации в сервисе, точку монтирования и автозапуск.
Согласно плану создания резервных копий БД, создадим 3 скрипта, которые будут создавать ежедневные, еженедельные и ежемесячные бэкапы с разными сроками хранения.
Ежедневный скрипт:
mcedit /backup/everyday-backup-pgsql.shСодержимое:
#!/bin/bash # Задаем переменные: TIME=`date +»%Y-%m-%d_%H-%M»`
# Записываем информацию о начале бэкапа в лог: echo «`date +»%Y-%m-%d_%H-%M-%S»` Start backup» >> /backup/pgsql-everyday-backup.log
# Бэкапим и архивируем. При бэкапе еще одной базы — копируем эту команду с заменой имени базы с учетом регистра. pg_dump -U postgres UPP | pigz > /backup/everyday/$TIME-UPP.sql.gz
# Загружаем данные на Яндекс.Диск cp /backup/everyday/$TIME-UPP.sql.gz /Yandex.Disk/everyday
# Записываем информацию о завершении бэкапа в лог: echo «`date +»%Y-%m-%d_%H-%M-%S»` End backup» >> /backup/pgsql-everyday-backup.log
# Удаляем файлы старше 5 дней с локального диска find /backup/everyday -type f -mtime +5 -exec rm -rf {} \;
# Удаляем файлы старше 3 дней с Яндекс.Диск. find /Yandex.Disk/everyday -type f -mtime +3 -exec rm -rf {} \;
Еженедельный скрипт:
mcedit /backup/everyweek-backup-pgsql.shСодержимое:
#!/bin/bash# Задаем переменные:TIME=`date +»%Y-%m-%d_%H-%M»`
# Записываем информацию о начале бэкапа в лог:echo «`date +»%Y-%m-%d_%H-%M-%S»` Start backup» >> /backup/pgsql-everyweek-backup.log
# Бэкапим и архивируем. При бэкапе еще одной базы — копируем эту команду с заменой имени базы с учетом регистра.pg_dump -U postgres UPP | pigz > /backup/everyweek/$TIME-UPP.sql.gz
# Загружаем данные на Яндекс.Дискcp /backup/everyweek/$TIME-UPP.sql.gz /Yandex.Disk/everyweek
# Записываем информацию о завершении бэкапа в лог:echo «`date +»%Y-%m-%d_%H-%M-%S»` End backup» >> /backup/pgsql-everyweek-backup.log
# Удаляем файлы старше 3 дней с локального дискаfind /backup/everyweek -type f -mtime +3 -exec rm -rf {} \;
# Удаляем файлы старше 2 дней с Яндекс.Диск.find /Yandex.Disk/everyweek -type f -mtime +2 -exec rm -rf {} \;
Ежемесячный скрипт:
mcedit /backup/everymonth-backup-pgsql.shСодержимое:
#!/bin/bash# Задаем переменные:TIME=`date +»%Y-%m-%d_%H-%M»`
# Записываем информацию о начале бэкапа в лог:echo «`date +»%Y-%m-%d_%H-%M-%S»` Start backup» >> /backup/pgsql-everymonth-backup.log
# Бэкапим и архивируем. При бэкапе еще одной базы — копируем эту команду с заменой имени базы с учетом регистра.pg_dump -U postgres UPP | pigz > /backup/everymonth/$TIME-UPP.sql.gz
# Загружаем данные на Яндекс.Дискcp /backup/everymonth/$TIME-UPP.sql.gz /Yandex.Disk/everymonth
# Записываем информацию о завершении бэкапа в лог:echo «`date +»%Y-%m-%d_%H-%M-%S»` End backup» >> /backup/pgsql-everymonth-backup.log
# Удаляем файлы старше 2 дней с локального дискаfind /backup/everymonth -type f -mtime +2 -exec rm -rf {} \;
# Удаляем файлы старше 1 дней с Яндекс.Диск.find /Yandex.Disk/everymonth -type f -mtime +1 -exec rm -rf {} \;
Даём скриптам права на запуск:
chmod 0700 /backup/everyday-backup-pgsql.sh chmod 0700 /backup/everyweek-backup-pgsql.sh chmod 0700 /backup/everymonth-backup-pgsql.shДля временного хранения архивных копий создадим соответствующие папки everyday, everyweek, everymonth:
mkdir /backup/everyday mkdir /Yandex.Disk/everyday mkdir /backup/everyweek mkdir /Yandex.Disk/everyweek mkdir /backup/everymonth mkdir /Yandex.Disk/everymonthТак как системный раздел небольшой, перенесем папку Yandex.Disk в backup:
mv /Yandex.Disk /backupСоздадим символьную ссылку:
ln -s /backup/Yandex.Disk /Yandex.DiskДобавим задание в crontab:
mcedit /etc/crontabДобавим расписание резервного копирования:
# Выгрузка БД в будние дни в полночь00 00 * * 1 root /backup/everyday-backup-pgsql.sh00 00 * * 2 root /backup/everyday-backup-pgsql.sh00 00 * * 3 root /backup/everyday-backup-pgsql.sh00 00 * * 4 root /backup/everyday-backup-pgsql.sh00 00 * * 5 root /backup/everyday-backup-pgsql.sh
# Выгрузка БД каждое воскресенье в полночь30 0 * * 7 root /backup/everyweek-backup-pgsql.sh
# Выгрузка БД каждое 1-ое число месяца в 00:300 1 1 * * root /backup/everymonth-backup-pgsql.sh
В файле cron’а должна быть последняя пустая строка. Если файл cron’а редактировали во внешнем редакторе, тогда делаем:
crontab -eВ нем пишем:
:w
:q
Восстановление базы данных из резервной копии (бэкапа)
После создания резервной копии, можем проверить, восстанавливается ли из нее база данных.
Первым делом разархивируем файл:
unpigz -c /backup/everyday/YYYY-mm-dd_HH-MM-UPP.sql.gz > UPP.sqlТак как настоятельно не рекомендуется восстанавливать копию в рабочую базу, то создадим на сервере новую базу данных, в которую будем восстанавливать резервную копию. Перед этим посмотрим список баз данных на сервере:
Создаем новую базу данных upp-temp:
# createdb --username postgres -T template0 upp-tempВ созданную базу данных загрузим резервную копию:
psql -U postgres upp-temp < /backup/everyday/UPP.sqlПосле завершения восстановления, в консоле кластера 1С добавим новую базу. В качестве базы postgresql укажем созданную базу с загруженной копией.
Обновление статистики и реиндексация в PostgreSQL
Настроим регламентные операции в PostgreSQL для предотвращения падения производительности базы данных.
Будем выполнять очистку и анализ базы данных, а также реиндексацию ее таблиц.
Оформим регламентные операции в виде скрипта и будем исполнять его по расписанию.
Создадим скрипт everyday-service-pgsql.sh:
mcedit /backup/everyday-service-pgsql.shЗапишем в него следующее содержимое:
#!/bin/sh
# Записываем информацию о начале очистки БД в логecho «`date +»%Y-%m-%d_%H-%M-%S»` Start vacuum» >> /backup/service.log
# Выполняем очистку и анализ базы данных/usr/bin/vacuumdb —full —analyze —username postgres —dbname UPP
# Записываем информацию об окончании очистки БД в логecho «`date +»%Y-%m-%d_%H-%M-%S»` End vacuum» >> /backup/service.log
# Ставим на паузу выполнение скрипта на 10 секундsleep 10
# Записываем информацию о начале переиндексации таблиц БД в логecho «`date +»%Y-%m-%d_%H-%M-%S»` Start reindex» >> /backup/service.log
# Переиндексируем таблицы базы данных/usr/bin/reindexdb —username postgres —dbname UPP
# Записываем информацию об окончании переиндексации таблиц БД в логecho «`date +»%Y-%m-%d_%H-%M-%S»` End reindex» >> /backup/service.log
Дадим скрипту право на запуск:
chmod 0700 /backup/everyday-service-pgsql.shДобавим исполнение данного скрипта в расписание cron. Осуществлять запуск будем ежедневно после резервного копирования, в данном случае на 2 часа ночи:
# Исполнение скрипта регламентных операций 00 02 * * * root /backup/everyday-service-pgsql.sh
Поделиться ссылкой:
Похожее
Резервное копирование баз данных postgresql
26 января 2014 г. 14:55
Бекап базы данных
Все знают насколько важна задача резервирования данных, и чем скорее вы это сделаете, тем спокойнее будет. Существуют многие подходы к решению данной задачи. Я лишь опишу свой с ответами на вставшие передо мной вопросы:
- Создание бекапа БД postgresql без пароля утилитой pg_dump.
- Написание скрипта, который создаёт бекап базы данных (с сжатием) картинкок.
- Добавление задания в cron.
Так как резервное копирование должно осуществляться периодически, например, каждый день, то необходимо сделать так, чтобы бекап происходил без пароля. На просторах интернета я наткнулся на примеры:
pg_dump -h localhost -p 5432 -U user_name -F c -b -v -f mydb.backup mydb pg_dump -U user_name -F c -v -f /home/test_db.backup test_dbкоторый из которых прекрасно делает бекап, но требует пароль.
Чтобы производился бекап без пароля, нужно в файле /etc/postgresql/9.1/main/pg_hba.conf найти строку local all all peer и значение peer заменить на trust:
local all all trustТеперь при выполнении команды:
pg_dump -U vivazzi -F c -f test_db.backup test_dbВосстановление базы данных из бекапа
Чтобы восстановить базу данных, можно воспользоваться следующими командами:
pg_restore -U postgres -d project /path/to/db/ pg_restore --host localhost --port 5432 --username user --dbname test2 --verbose /home/test/db.backup pg_restore --host 62.109.10.27 --port 5432 --username "user" --dbname "db_test" --no-password --verbose "E:\db.backup"Бекап и восстановление всех баз данных
Создание дампа всех баз данных:
pg_dumpall > output_fileПро pg_dumpall ещё можно почитать здесь: http://postgresql.ru.net/manual/backup-dump.html
Чтобы восстановить дамп всех баз данных, нужно зайти в pg_hba.conf (/etc/postgresql/9.1/main/pg_hba.conf) и поменять строчку local all postgres peer на:
local all postgres trustЗатем выполнить команду:
sudo psql -f path/to/db -U postgres postgresОцените статью
5 из 5 (всего 2 оценки)Поля, отмеченные звёздочкой ( * ) , являются обязательными.
Спасибо за ваш отзыв!
После нажатия кнопки "Отправить" ваше сообщение будет доставлено мне на почту.

Мальцев Артём
Веб-разработчик, владеющий знаниями языка программирования Python, фреймворка Django, системы управления содержимым сайта Django CMS, платформы для создания интернет-магазина Django Shop и многих различных приложений, использующих эти технологии.
Права на использование материала, расположенного на этой странице http://vivazzi.pro/it/backup-postgresql/:
Разрешается копировать материал с указанием её автора и ссылки на оригинал без использования параметра rel="nofollow" в теге <a>. Использование:
Автор статьи: Мальцев АртёмСсылка на статью: <a href="http://vivazzi.pro/it/backup-postgresql/">http://vivazzi.pro/it/backup-postgresql/</a>Подробнее: Правила использования сайта
Похожие статьи:
vivazzi.pro
Резервное копирование баз данных PostgreSQL
Для реализации простейшего резервного копирования баз данных postgres я не стал использовать какие-либо сложные backup-решения, а остановился на простейшем database dump.В /usr/local/bin создал файл скрипт следующего содержания:Данный файл прописываем в cron для пользователя root, с вызовом или по рабочим дням, или ежедневно. Для возможности запуска sudo из cron-задания, следует разрешить sudo для пользователя root - добавить строки видаDefaults:root !requiretty
Defaults:!root requiretty
в /etc/sudoers. Проверяем результат на следующий день.Из недостатков предложенного метода хотелось бы отметить необходимость вызова данного скрипта суперпользователем (к стати, наверное его следовало положить в /usr/local/sbin, для большей безопасности, но тогда в syslog появлялся мусор типа "Can't change path to /usr/local/sbin", судя по всему, на этапе вычисления `date \+\%Y-\%m-\%d`), но я не нашёл другого метода запускать pg_dump, не зная пароль пользователя postgres или не указывая его в явном виде.В принципе, вместо конструкции sudo, можно использовать pg_dump --superuser=ИМЯСУПЕРПОЛЬЗОВАТЕЛЯ -w $dump_base для подключения без пароля - такую конструкцию можно использовать и на windows-установке Postgre SQL, но только в случае, если есть "суперпользователь" без пароля, которому разрешены только локальные подключения - каждому выбирать самостоятельно.
Доработанный скрипт.
В условиях отсутствия локального или сетевого тома для хранения резервных копий (несколько натянутое условие, но мне пришлось столкнуться), пришлось доработать скрипт; отличие от изначального скрипта - результат дампа не сохраняется локально, а передаётся на удалённый сервер по ssh и там же производится удаление устаревших файлов:
#!/bin/sh# Для инструкций по восстановлению см. postgresql.org/docs/8.1/static/backup.html# Путь на сервере резервирования, куда будем складывать резервные копииdump_path="/mnt/backup/pgsql"# Устанавливаем разделитель для элементов массива, предварительно резервируя системный:oldIFS==$IFSIFS=";"# Названия баз данных, которые будем сохранять, перечисленные через разделитель, заданный вышеdump_bases="office_upp;buh_retail;zup"# Срок хранения резервных копий, дней:dump_keepdays="7"# Создаём информационный файл в каталоге назначения ("для будущих поколений")ssh -i /root/nbs01/backup [email protected] \ "echo `date \+\%F\ \%T` Dumps of databases. For restoring see postgresql.org/docs/9.3/static/backup.html > $dump_path/readme.txt"for dump_base in $dump_bases; do# Создаём дамп от имени пользователя postgres, передавая текстовый дамп по ssh на удалённый сервер,# сжимая там результат gzip'ом и сохраняя в файл с именем вида %dbname%-yyyy-mm-dd-hh-mm-ss.pgdump.gz sudo -u postgres pg_dump -Fc $dump_base | ssh -i /root/nbs01/backup [email protected] \ "gzip > $dump_path/$dump_base-`date \+\%Y-\%m-\%d-\%H-\%M-\%S`.pgdump.gz" # Ищем в каталоге резервных копий все файлы с именами похожими на бэкап текущей БД и старше срока хранения и удаляем ssh -i /root/nbs01/backup [email protected] \ "find $dump_path/$dump_base* -mtime +$dump_keepdays -exec /bin/rm '{}' \;"donessh -i /root/nbs01/backup [email protected] \ "echo `date \+\%F\ \%T` All data keeps $dump_keepdays days, older files will be removed automatically. >> $dump_path/readme.txt"# Восстанавливаем стандартный (системный) разделитель списковIFS=$oldIFS
Предварительно надо создать авторизационный ключ для пользователя (в приведённом скрипте пользователь - backup) на сервере резервного хранения и разместить приватный ключ в каталоге, доступном на чтение только пользователю root (в приведённом скрипте ключ лежит в файле /root/nbs01/backup) и настроить sshd удалённого сервера на авторизацию по ключам - об этом весьма подробно написано, например, в этой статье. Да, трафик будет весьма серьёзным, несмотря на возможность сжатия ssh, но конкретно данное решение работает в виртуальной среде, где 3 гигабайта дампа передаются примерно за полторы минуты, что вполне приемлемо.Используемый скрипт для Windows
Недавно попросили настроить 1С и PostgreSQL в Windows, на скорую руку набросал скрипт резервного копирования базы (к сожалению, замечаний пока много, но времени на "шлифовку" было сильно мало - переделывал древний скрипт архивирования файловой базы). Для резервного копирования используется FTP, для работы с которым я пользуюсь привычным curl (прошу обратить внимание, что если Вы не хотите компилировать его из исходников, надо скачать готовый пакет для Windows; скрипт предполагает, что curl.exe лежит рядом со скриптом):@Echo off: Скрипт создаёт архив томами по 4480 Мб (размер DVD), добавляя к ARCNAMEBEGIN: текущую дату в формате -ГГГГ-ММ-ДД с расширением ARCEXT, помещая в него всё: из каталога BACKUPPATH: При успешном завершении архивации, удаляются все архивы, начинающиеся с: ARCNAMEBEGIN и имеющие расширение ARCEXT (и тома) старше KEEPDAYS дней: ВАЖНО!!!: ARCNAMEBEGIN должен начинаться с буквы диска, т.к. ForFiles не работает с: путями UNC (по крайней мере на имеющейся у меня версии Windows): Для возможности резервного копирования на локально подключенный диск и на: сетевой общий ресурс, добавлены команды 'net use';: Результат работы скрипта сохраняется в файле LOG (полное имя файла) в: кодировке CP866: Результат текущей архивации сохраняется в файл LOG.txt (там же где и основной: протокол, но с добавлением расширения .txt; перезаписывается при каждом: запуске) в кодировке UTF-8 и при возникновении ошибок отправляется на e-mail: вызовом скрипта BackupSendError.vbs расположенного рядом с данным: Подключение сетевого хранилища, при необходимости: net use t: /delete: net use t: \\NBS\Fileserver$
: Полный путь к файлу журнала:SET LOG=D:\BackUp\Log\Backup.log: Полный путь и начало имени архивов:SET ARCNAMEBEGIN=D:\BackUp\7z\retail_o: Расширение файла архива:SET ARCEXT=7z: Полный путь к архивируемому каталогу:SET BACKUPPATH=D:\BackUp\retail_o.sql: SET BACKUPPATH=D:\TechShare: Срок хранения архивов (архивы старше этого срока будут удалены при архивации)SET KEEPDAYS=30
: Пользователь и пароль FTPSET FTPUSER=magazinSET FTPPW=SuperPassword call :getdate"C:\Program Files\PostgresPro 1C\9.6\bin\pg_dump.exe" --dbname="postgresql://postgres:SuperPassword@localhost:5432/buh" > %BACKUPPATH%
call :arch %ARCNAMEBEGIN% %BACKUPPATH% >> "%LOG%"
%~dp0curl.exe -u
%FTPUSER%:%FTPPW% -T "%ARCNAMEBEGIN%-%Year%-%Month%-%Day%.%ARCEXT%" ftp://magazin:@192.168.20.77:21/exchange/BackUp/: Отключение сетевого хранилища, при необходимости: net use t: /delete
exit
:deloldif not exist "%1" Echo %DATE% %TIME% Path %1 NOT FOUND!!!if not exist "%1" exit /bEcho %DATE% %TIME% Deleting all %2 files in %1 folder, older than %3 daysForfiles -p %1 -s -m %2 -d -%3 -c "%comspec% /c del /q @path" > nulecho %DATE% %TIME% Clearing done with errorlevel: %errorlevel%exit /b
:archecho %DATE% %TIME% ----------------------------------------------------------echo %DATE% %TIME% Starting archiving files from %2 to %1-%Year%-%Month%-%Day%.%ARCEXT%echo %DATE% %TIME% User: %USERNAME%: "C:\Program Files\7-Zip\7z.exe" a -r -ssw -sccUTF-8 -v4480m -mx=3 -ms=off -y "%1-%Year%-%Month%-%Day%.%ARCEXT%" "%2" > %LOG%.txt"C:\Program Files\7-Zip\7z.exe" a -ssw -sccUTF-8 -mx=3 -ms=off -y "%1-%Year%-%Month%-%Day%.%ARCEXT%" "%2" > %LOG%.txtecho %DATE% %TIME% Archiving done with errorlevel: %errorlevel%if not errorlevel 1 (call :delold %~dp1 %~n1*.%ARCEXT%* %KEEPDAYS%) else (cscript %~dp0BackupSendError.vbs //Nologo %LOG%.txt)echo %DATE% %TIME% Backup doneexit /b
:getdate: Чтение текущей даты в переменные окружения For /F "Tokens=1,3" %%i IN ('REG QUERY "HKCU\Control Panel\International" /s^|FindStr /C:"iDate" /C:"sDate"') DO Set %%i=%%j For /F "Tokens=1-4* Delims=%sDate% " %%A IN ("%Date%") Do ( If %iDate% EQU 0 Set Year=%%C&Set Month=%%A&Set Day=%%B If %iDate% EQU 1 Set Year=%%C&Set Month=%%B&Set Day=%%A If %iDate% EQU 2 Set Year=%%A&Set Month=%%B&Set Day=%%C )exit /b
Восстановление базы данных из дампа.
На практике я последнее время создаю текстовые дампы ("доработанный скрипт"), а восстанавливаю командой:
psql upp-copy < upp-2014-06-27-14-30-04.pgdump > log-create
"upp-copy" - имя базы данных, в которую производится восстановление; "upp-2014-06-27-14-30-04.pgdump" - имя файла дампа базы; "log-create" - файл, в который помещаются сообщения об успешно созданных таблицах и т.п., иначе можно не увидеть ошибок за кучей диагностики (да и в удалённой сессии это несколько увеличивает производительность). Команда отдаётся от рута (ему я разрешил локальный доступ к pgsql). Важным является то, что на момент восстановления, база должна существовать, быть пустой, и иметь владельца, совпадающего с владельцем оригинальной базы.
Для двоичных дампов несколько иначе:
Если владелец (имя "роли входа" или пользователь postgresql, указанный владельцем изначальной БД) уже существует, но нет самой базы данных, команда восстановления будет выглядеть примерно так:
/usr/pgsql-9.2/bin/pg_restore -e -j 8 -U root -W -d upp /root/files/upp-2013-11-20.pgdump
Восстановление будет выполнено в 8 потоков (для ускорения процедуры, в документации pgsql рекомендуется использовать потоков не меньше, чем доступно ядер CPU) от имени пользователя root с интерактивным вводом пароля. Файл /mnt/arc/1C8/upp-2013-11-20-09-45-51.pgdump - распакованный .gz из второго примера или изначальный дамп из первого. Целевая база (в данном примере - upp) должна уже существовать, и быть созданной из template0.
Если пользователя-владельца создать нет возможности/желания, можно добавить ключ --no-owner да и вообще, почитать что пишут на http://www.postgresql.org/docs/9.3/static/backup.html
И ещё, если на создание дампа в пару гигабайт (несжатых) уходит пара минут, то на восстановление данного дампа в один поток (если не указать ключ распараллеливания - "-j 8" в примере выше) потребуется уже полчасика, на том же железе. А если использовать текстовые дампы (не указать "-F c" при создании дампа, и для восстановления использовать стандартную команду psql dbname < infile или использовать конвейер типа pg_restore infile.pgdump | psql), времени потребуется ещё больше - данные методы целесообразно использовать не для полного восстановления, а когда требуется восстановить только определённую часть базы данных.
*При восстановлении не в тестовой среде, а в "условно боевой" ситуации (на совершенно другой сервер), проявилась особенность - для корректного восстановления базы данных, необходимо, чтобы на "новом" сервере существовал пользователь, являющийся владельцем объектов сохранённой (восстанавливаемой) базы - в моём случае, на исходном сервере был владелец БД server1c, а на целевом по рассеянности пользователя назвали server1c8, из-за чего восстановление прошло с ошибками и пришлось разворачивать БД заново, создав нужного пользователя.
bubnov-pi.blogspot.com
PostgreSQL : Документация: 9.4: Резервное копирование на уровне файлов : Компания Postgres Professional
Альтернативной стратегией резервного копирования является непосредственное копирование файлов, в которых PostgreSQL хранит содержимое базы данных; в Разделе 17.2 рассказывается, где находятся эти файлы. Вы можете использовать любой способ копирования файлов по желанию, например:
tar -cf backup.tar /usr/local/pgsql/dataОднако, существуют два ограничения, которые делают этот метод непрактичным или как минимум менее предпочтительным по сравнению с pg_dump:
Чтобы полученная резервная копия была годной, сервер баз данных должен быть остановлен. Такие полумеры, как запрещение всех подключений к серверу, работать не будут (отчасти потому что tar и подобные средства не получают мгновенный снимок состояния файловой системы, но ещё и потому, что в сервере есть внутренние буферы). Узнать о том, как остановить сервер, можно в Разделе 17.5. Необходимо отметить, что сервер нужно будет остановить и перед восстановлением данных.
Если вы ознакомились с внутренней организацией базы данных в файловой системе, у вас может возникнуть соблазн скопировать или восстановить только отдельные таблицы или базы данных в соответствующих файлах или каталогах. Это не будет работать, потому что информацию, содержащуюся в этих файлах, нельзя использовать без файлов журналов транзакций, pg_clog/*, которые содержат состояние всех транзакций. Без этих данных файлы таблиц непригодны к использованию. Разумеется также невозможно восстановить только одну таблицу и соответствующие данные pg_clog, потому что в результате нерабочими станут все другие таблицы в кластере баз данных. Таким образом, копирование на уровне файловой системы будет работать, только если выполняется полное копирование и восстановление всего кластера баз данных.
Ещё один подход к резервному копированию файловой системы заключается в создании "целостного снимка" каталога с данными, если это поддерживает файловая система (и вы склонны считать, что эта функциональность реализована корректно). Типичная процедура включает создание "замороженного снимка" тома, содержащего базу данных, затем копирование всего каталога с данными (а не его избранных частей, см. выше) из этого снимка на устройство резервного копирования, и наконец освобождение замороженного снимка. При этом сервер базы данных может не прекращать свою работу. Однако резервная копия, созданная таким способом, содержит файлы базы данных в таком состоянии, как если бы сервер баз данных не был остановлен штатным образом; таким образом, когда вы запустите сервер баз данных с сохранёнными данными, он будет считать, что до этого процесс сервера был прерван аварийно, и будет накатывать журнал WAL. Это не проблема, просто имейте это в виду (и обязательно включите файлы WAL в резервную копию). Чтобы сократить время восстановления, можно выполнить команду CHECKPOINT перед созданием снимка.
Если ваша база данных размещена в нескольких файловых системах, получить в точности одновременно замороженные снимки всех томов может быть невозможно. Например, если файлы данных и журналы WAL находятся на разных дисках или табличные пространства расположены в разных файловых системах, резервное копирование со снимками может быть неприменимо, потому что снимки должны быть одновременными. В таких ситуациях очень внимательно изучите документацию по вашей файловой системе, прежде чем довериться технологии согласованных снимков.
Если одновременные снимки невозможны, остаётся вариант с остановкой сервера баз данных на время, достаточное для получения всех замороженных снимков. Другое возможное решение — получить базовую копию путём непрерывного архивирования (см. Подраздел 24.3.2), такие резервные копии не могут пострадать от изменений файловой системы в процессе резервного копирования. Для этого требуется включить непрерывное архивирование только на время резервного копирования; для восстановления применяется процедура восстановления из непрерывного архива (Подраздел 24.3.4).
Ещё один вариант — копировать содержимое файловой системы с помощью rsync. Для этого rsync запускается сначала во время работы сервера баз данных, а затем сервер останавливается на время, достаточное для второго запуска rsync. Во второй раз rsync отработает намного быстрее, чем в первый, потому что скопировать надо будет относительно немного данных; и в итоге будет получен согласованный результат, так как сервер был остановлен. Данный метод позволяет получить копию на уровне файловой системы с минимальным временем простоя.
Обратите внимание, что размер копии на уровне файлов обычно больше, чем дампа SQL. (Программе pg_dump не нужно, например, записывать содержимое индексов, достаточно команд для их пересоздания). Однако копирование на уровне файлов может выполняться быстрее.
postgrespro.ru
Резервное копирование баз данных PostgreSQL
Перед всеми системными администраторами возникает задача резервного копирования баз данных (БД). Поэтому хочу поделится с вами скриптом для резервного копирования БД PostgreSQL. И его довольно просто переделать для любой другой СУБД. Данный скрипт неплохо подойдет новичкам. На нашем форуме есть вариант скрипта для резерного копирования БД MySQL.
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | #!/bin/bash HOST="hostname" # Имя хоста на котором будем выполнять скрипт, можно и не использовать DUMPER="/usr/bin/pg_dump" # Указываем утилиту резервного копирования (дампа). #DUMPPARAM1="-Q -c -e" # -Q оборачивает имена обратными кавычками, # -c делает полную вставку, включая имена колонок, # -e делает расширенную вставку. # Итоговый файл получается меньше и создается он чуть быстрее. #DBUSER="dbuser" # Внутренний пользователь сервера БД от имени которого будет выполнятся бэкап #DBPASS="passwd" # Пароль внутреннего пользователя mysql DBNAME="dbname" # Имя БД с которой будет создана резервная копия DATE=`date +%F_%H.%M` # Задаем дату и время бекапа FIND="/usr/bin/find" # Указываем утилиту для поиска FINDPARAM1="-type f -ctime +7" # Где +7 - архивы старше семи дней FINDPARAM2="-delete" # Параметры удаления BACKUPDIR="/var/backups/psql/" # Директория, где будут хранится резервные копии # Дамп БД, где DBUSER - имя пользователя, DBNAME - имя базы данных, архив имеет следующий формат. # Имя базы данных, имя хоста, дата и время, расширение gz: $DBNAME-2016-02-29_14.30.sql.gz $DUMPER $DBNAME | gzip > $BACKUPDIR$DBNAME.$HOST-$DATE.sql.gz # Пауза sleep 3 # Удаляем старые архивы, а точней файлы старше 7 дней, так же удаляем пустые каталоги. eval $FIND $BACKUPDIR $FINDPARAM1 $FINDPARAM2 exit 0 |
Хочу напомнить, что данный скрипт нужно выполнять от имени пользователя postgres. Неиспользуемые переменные закомментированы, при желании можно их удалить.
Восстановить дамп можно командой:
| 1 | $ gunzip < /var/backups/psql/archname.sql.gz | psql dbname |
Где archname - имя резервной копии (дампа), а dbname - имя существующей БД в PostgreSQL. Если хотите восстановить дамп в новую БД, то создать ее можно командой:
Опять же, команду необходимо выполнять от имени postgres.
Теперь осталось настроить время запуска скрипта. В этом нам поможет cron. Мне необходимо чтобы скрипт запускался:- ежедневно в 22:30, с понедельника по пятницу,- ежемесячно в 23:30, в первую субботу месяца.
Кроме того, ежедневные и ежемесячные копии должны хранится отдельно. Соответственно нам потребуются две копии скрипта, в каждной укажем необходимый путь для резерных копий:
| 1 2 | /var/backups/psql/dayli /var/backups/psql/monthly |
С помощью команды crontab:
Добавим в список заданий пару строк в самый конец файла:
| 1 2 | 30 22 * * 1-5 postgres /path/psql_dayli-backup.sh # Ежедневно, с пн. по пт. 30 23 1-7 * [ "$(date '+\%u')" -eq 6 ] && /path/psql_monthly-backup.sh postgres # Ежемесячно, в первую сб. |
Где postgres - пользователь, от имени которого будет запускаться скрипт, path - путь до каталога со скриптами, а psql_dayli-backup.sh и psql_monthly-backup.sh - имена файлов со скриптом.
nixway.org
PostgreSQL : Документация: 9.6: 25.2. Резервное копирование на уровне файлов : Компания Postgres Professional
25.2. Резервное копирование на уровне файлов
Альтернативной стратегией резервного копирования является непосредственное копирование файлов, в которых PostgreSQL хранит содержимое базы данных; в Разделе 18.2 рассказывается, где находятся эти файлы. Вы можете использовать любой способ копирования файлов по желанию, например:
tar -cf backup.tar /usr/local/pgsql/dataОднако, существуют два ограничения, которые делают этот метод непрактичным или как минимум менее предпочтительным по сравнению с pg_dump:
Чтобы полученная резервная копия была годной, сервер баз данных должен быть остановлен. Такие полумеры, как запрещение всех подключений к серверу, работать не будут (отчасти потому что tar и подобные средства не получают мгновенный снимок состояния файловой системы, но ещё и потому, что в сервере есть внутренние буферы). Узнать о том, как остановить сервер, можно в Разделе 18.5. Необходимо отметить, что сервер нужно будет остановить и перед восстановлением данных.
Если вы ознакомились с внутренней организацией базы данных в файловой системе, у вас может возникнуть соблазн скопировать или восстановить только отдельные таблицы или базы данных в соответствующих файлах или каталогах. Это не будет работать, потому что информацию, содержащуюся в этих файлах, нельзя использовать без файлов журналов транзакций, pg_clog/*, которые содержат состояние всех транзакций. Без этих данных файлы таблиц непригодны к использованию. Разумеется также невозможно восстановить только одну таблицу и соответствующие данные pg_clog, потому что в результате нерабочими станут все другие таблицы в кластере баз данных. Таким образом, копирование на уровне файловой системы будет работать, только если выполняется полное копирование и восстановление всего кластера баз данных.
Ещё один подход к резервному копированию файловой системы заключается в создании «целостного снимка» каталога с данными, если это поддерживает файловая система (и вы склонны считать, что эта функциональность реализована корректно). Типичная процедура включает создание «замороженного снимка» тома, содержащего базу данных, затем копирование всего каталога с данными (а не его избранных частей, см. выше) из этого снимка на устройство резервного копирования, и наконец освобождение замороженного снимка. При этом сервер базы данных может не прекращать свою работу. Однако резервная копия, созданная таким способом, содержит файлы базы данных в таком состоянии, как если бы сервер баз данных не был остановлен штатным образом; таким образом, когда вы запустите сервер баз данных с сохранёнными данными, он будет считать, что до этого процесс сервера был прерван аварийно, и будет накатывать журнал WAL. Это не проблема, просто имейте это в виду (и обязательно включите файлы WAL в резервную копию). Чтобы сократить время восстановления, можно выполнить команду CHECKPOINT перед созданием снимка.
Если ваша база данных размещена в нескольких файловых системах, получить в точности одновременно замороженные снимки всех томов может быть невозможно. Например, если файлы данных и журналы WAL находятся на разных дисках или табличные пространства расположены в разных файловых системах, резервное копирование со снимками может быть неприменимо, потому что снимки должны быть одновременными. В таких ситуациях очень внимательно изучите документацию по вашей файловой системе, прежде чем довериться технологии согласованных снимков.
Если одновременные снимки невозможны, остаётся вариант с остановкой сервера баз данных на время, достаточное для получения всех замороженных снимков. Другое возможное решение — получить базовую копию путём непрерывного архивирования (см. Подраздел 25.3.2), такие резервные копии не могут пострадать от изменений файловой системы в процессе резервного копирования. Для этого требуется включить непрерывное архивирование только на время резервного копирования; для восстановления применяется процедура восстановления из непрерывного архива (Подраздел 25.3.4).
Ещё один вариант — копировать содержимое файловой системы с помощью rsync. Для этого rsync запускается сначала во время работы сервера баз данных, а затем сервер останавливается на время, достаточное для запуска rsync --checksum. (Ключ --checksum необходим, потому что rsync различает время только с точностью до секунд.) Во второй раз rsync отработает быстрее, чем в первый, потому что скопировать надо будет относительно немного данных; и в итоге будет получен согласованный результат, так как сервер был остановлен. Данный метод позволяет получить копию на уровне файловой системы с минимальным временем простоя.
Обратите внимание, что размер копии на уровне файлов обычно больше, чем дампа SQL. (Программе pg_dump не нужно, например, записывать содержимое индексов, достаточно команд для их пересоздания). Однако копирование на уровне файлов может выполняться быстрее.
postgrespro.ru
Бэкап и восстановление базы 1С в бд postgresql, обслуживание базы, чистка логов PostgreSQL
Бэкап и восстановление базы 1С в бд postgresql, обслуживание базыОпыт обслуживания базы 1С в PostgreSQLРезервное копирование баз данных PostgreSQLМожет возникнуть ситуация при которой файл .dt будет выгружаться средствами 1с,но при обратной загрузке или загрузке в файловую базу, загружаться не будет (при ошибках в базе).Файл .dt может считаться бэкапом только при условии проверки загрузки! Поэтому необходимо организовать бэкап средствами базы данных./home/user/test/ - папка с доступом по ftp (test test) (ранее подготовлена)
Подготовка:$ sudo mkdir /home/user/test/backup$ sudo chmod -R 777 /home/user/test/backup $ sudo apt-get -y install pigz
Бэкап с архивированием: $ sudo su - postgres$ pg_dump demo | pigz > /home/user/test/backup/demo.sql.gz
Разархивирование с сохранением архива $ sudo su - postgres $ unpigz -c /home/user/test/backup/demo.sql.gz > /home/user/test/backup/demo.sql
Создадим базу demotest (если еще не создана)$ sudo su - postgres $ createdb --username postgres -T template0 demotest
Восстановим в базу demotest:$ psql -l$ unpigz -c /home/user/test/backup/demo.sql.gz > /home/user/test/backup/demo.sql $ psql demotest < /home/user/test/backup/demo.sql
Подключимся к базе средствами 1С:
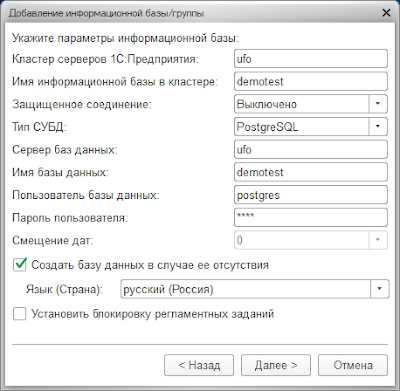
Базу demotest можно оставить для регулярного тестирования бэкапов.
Убьем базу demotest: sudo su - postgres$ dropdb demotest$ psql -l
----------------------------------------------------------------------------------------------------------------- Для автоматического создания бекапов:Зададим папку, если не делали раньше,см. начало статьи!
Папка с бэкапами будет доступна по ftp (test test)Подготовка:$ sudo mkdir /home/user/test/backup$ sudo chmod -R 777 /home/user/test/backup $ sudo apt-get -y install pigz$ sudo su - postgres $ nano /home/user/test/backup/backup-sql.sh
Вставить:
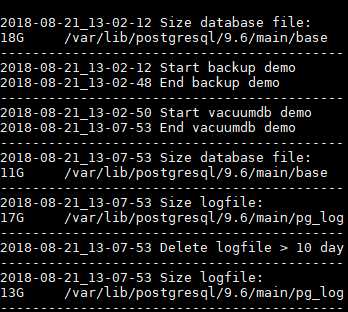
#!/bin/sh # Устанавливаем датуDATA=`date +"%Y-%m-%d_%H-%M"`echo "`date +"%Y-%m-%d_%H-%M-%S"` Size database file: " >> /home/user/test/backup/backup.log du -h -s /var/lib/postgresql/9.6/main/base >> /home/user/test/backup/backup.logecho "-------------------------------------------" >> /home/user/test/backup/backup.log# Записываем информацию в лог с секундамиecho "`date +"%Y-%m-%d_%H-%M-%S"` Start backup demo" >> /home/user/test/backup/backup.log
# Бэкапим базу данных demo и сразу сжимаем/usr/bin/pg_dump demo | pigz > /home/user/test/backup/$DATA-demo.sql.gz
echo "`date +"%Y-%m-%d_%H-%M-%S"` End backup demo" >> /home/user/test/backup/backup.log
sleep 2
echo "-------------------------------------------" >> /home/user/test/backup/backup.log
# Записываем информацию в лог с секундамиecho "`date +"%Y-%m-%d_%H-%M-%S"` Start vacuumdb demo" >> /home/user/test/backup/backup.log
vacuumdb --verbose --analyze --full --quiet --dbname=demo
echo "`date +"%Y-%m-%d_%H-%M-%S"` End vacuumdb demo" >> /home/user/test/backup/backup.log
echo "-------------------------------------------" >> /home/user/test/backup/backup.logecho "`date +"%Y-%m-%d_%H-%M-%S"` Size database file: " >> /home/user/test/backup/backup.log du -h -s /var/lib/postgresql/9.6/main/base >> /home/user/test/backup/backup.logecho "-------------------------------------------" >> /home/user/test/backup/backup.log
# Удаляем логи postgresql старше 10 днейecho "`date +"%Y-%m-%d_%H-%M-%S"` Size logfile: " >> /home/user/test/backup/backup.log du -h -s /var/lib/postgresql/9.6/main/pg_log >> /home/user/test/backup/backup.logecho "-------------------------------------------" >> /home/user/test/backup/backup.log echo "`date +"%Y-%m-%d_%H-%M-%S"` Delete logfile > 10 day " >> /home/user/test/backup/backup.logecho "-------------------------------------------" >> /home/user/test/backup/backup.log /usr/bin/find /var/lib/postgresql/9.6/main/pg_log -type f -mtime +10 -exec rm -rf {} \;echo "`date +"%Y-%m-%d_%H-%M-%S"` Size logfile: " >> /home/user/test/backup/backup.log du -h -s /var/lib/postgresql/9.6/main/pg_log >> /home/user/test/backup/backup.log echo "-------------------------------------------" >> /home/user/test/backup/backup.log
Сохранить.
Тестовый запуск: #$ cd /home/user/test/backup/$ sudo su - postgres $ sh /home/user/test/backup/backup-sql.sh
$ sudo su - postgres $ crontab -eДобавить в конец (сработает в 2:01):
#01 22 * * * vacuumdb --analyze --full --quiet --dbname=demo 01 02 * * * sh /home/user/test/backup/backup-sql.sh Сохранить Смотреть задания: $ crontab -lРегулярно восстанавливайте и проверяйте Бекапы средствами 1С!
Смотреть лог: $ sudo su - postgres$ nano /home/user/test/backup/backup.log
 Если мы хотим тот же скрипт выполнить от root модернизируем его предварительно отключив от postgres
Если мы хотим тот же скрипт выполнить от root модернизируем его предварительно отключив от postgres$ sudo su - postgres $ crontab -eЗакомментировать:
#01 22 * * * vacuumdb --analyze --full --quiet --dbname=demo #01 02 * * * sh /home/user/test/backup/backup-sql.sh Сохранить Выйти. $ exitТеперь заменим скрипт на следующий: $ nano /home/user/test/backup/backup-sql.sh
Вставить:
#!/bin/shset -e # останавливаем сервер 1Сsystemctl stop srv1cv83.servicesystemctl status srv1cv83.service >> /home/user/test/backup/backup.logecho "-------------------------------------------" >> /home/user/test/backup/backup.log# Устанавливаем датуDATA=`date +"%Y-%m-%d_%H-%M"`echo "`date +"%Y-%m-%d_%H-%M-%S"` Size database file: " >> /home/user/test/backup/backup.logdu -h -s /var/lib/postgresql/9.6/main/base >> /home/user/test/backup/backup.logecho "-------------------------------------------" >> /home/user/test/backup/backup.log# Записываем информацию в лог с секундамиecho "`date +"%Y-%m-%d_%H-%M-%S"` Start backup demo" >> /home/user/test/backup/backup.log
# Бэкапим базу данных demo и сразу сжимаемcd /home/user/test/backup//bin/su postgres -c "/usr/bin/pg_dump demo | pigz > /home/user/test/backup/$DATA-demo.sql.gz"echo "`date +"%Y-%m-%d_%H-%M-%S"` End backup demo" >> /home/user/test/backup/backup.logsleep 2echo "-------------------------------------------" >> /home/user/test/backup/backup.log# Записываем информацию в лог с секундамиecho "`date +"%Y-%m-%d_%H-%M-%S"` Start vacuumdb demo" >> /home/user/test/backup/backup.log/bin/su postgres -c "/usr/bin/vacuumdb --verbose --analyze --full --quiet --username postgres --dbname=demo"echo "`date +"%Y-%m-%d_%H-%M-%S"` End vacuumdb demo" >> /home/user/test/backup/backup.logecho "-------------------------------------------" >> /home/user/test/backup/backup.logecho "`date +"%Y-%m-%d_%H-%M-%S"` Size database file: " >> /home/user/test/backup/backup.logdu -h -s /var/lib/postgresql/9.6/main/base >> /home/user/test/backup/backup.logecho "-------------------------------------------" >> /home/user/test/backup/backup.log# Удаляем логи postgresql старше 10 днейecho "`date +"%Y-%m-%d_%H-%M-%S"` Size logfile: " >> /home/user/test/backup/backup.logdu -h -s /var/lib/postgresql/9.6/main/pg_log >> /home/user/test/backup/backup.logecho "`date +"%Y-%m-%d_%H-%M-%S"` Delete logfile > 5 day " >> /home/user/test/backup/backup.log/usr/bin/find /var/lib/postgresql/9.6/main/pg_log -type f -mtime +5 -exec rm -rf {} \; du -h -s /var/lib/postgresql/9.6/main/pg_log >> /home/user/test/backup/backup.logecho "-------------------------------------------" >> /home/user/test/backup/backup.log# запускаем сервер 1Сsystemctl start srv1cv83.servicesystemctl status srv1cv83.service >> /home/user/test/backup/backup.logecho "-------------------------------------------" >> /home/user/test/backup/backup.log
Сохранить.
$ sudo -i # crontab -eДобавить в конец (сработает в 2:01):
01 02 * * * sh /home/user/test/backup/backup-sql.sh Сохранить Смотреть задания: # crontab -l$ nano backup-sql.sh
#!/bin/shset -e # останавливаем сервер 1Сecho "останавливаем сервер 1С"systemctl stop srv1cv83.service#systemctl status srv1cv83.service >> /home/user/test/backup/backup.logecho "состояние сервера 1С" >> /home/user/test/backup/backup.logsystemctl status srv1cv83.service | grep 'Active:' >> /home/user/test/backup/backup.logecho "-------------------------------------------" >> /home/user/test/backup/backup.log# Устанавливаем датуDATA=`date +"%Y-%m-%d_%H-%M"`echo "`date +"%Y-%m-%d_%H-%M-%S"` Size database file: " >> /home/user/test/backup/backup.logdu -h -s /var/lib/postgresql/9.6/main/base >> /home/user/test/backup/backup.logecho "-------------------------------------------" >> /home/user/test/backup/backup.log# Записываем информацию в лог с секундамиecho "`date +"%Y-%m-%d_%H-%M-%S"` Start backup demo" >> /home/user/test/backup/backup.log# Бэкапим базу данных demo и сразу сжимаемecho "бэкапим базу данных demo"cd /home/user/test/backup//bin/su postgres -c "/usr/bin/pg_dump demo | pigz > /home/user/test/backup/$DATA-demo.sql.gz"echo "`date +"%Y-%m-%d_%H-%M-%S"` End backup demo" >> /home/user/test/backup/backup.logsleep 2echo "-------------------------------------------" >> /home/user/test/backup/backup.log# Записываем информацию в лог с секундамиecho "`date +"%Y-%m-%d_%H-%M-%S"` Start vacuumdb demo" >> /home/user/test/backup/backup.logecho "запускаем vacuum full"/bin/su postgres -c "/usr/bin/vacuumdb --verbose --analyze --full --quiet --username postgres --dbname=demo"echo "`date +"%Y-%m-%d_%H-%M-%S"` End vacuumdb demo" >> /home/user/test/backup/backup.logecho "-------------------------------------------" >> /home/user/test/backup/backup.logecho "`date +"%Y-%m-%d_%H-%M-%S"` Size database file: " >> /home/user/test/backup/backup.logdu -h -s /var/lib/postgresql/9.6/main/base >> /home/user/test/backup/backup.logecho "-------------------------------------------" >> /home/user/test/backup/backup.logsleep 2# запускаем сервер 1Сecho "запускаем сервер 1С"systemctl start srv1cv83.service#systemctl status srv1cv83.service >> /home/user/test/backup/backup.logecho "состояние сервера 1С" >> /home/user/test/backup/backup.logsystemctl status srv1cv83.service | grep 'Active:' >> /home/user/test/backup/backup.logecho "-------------------------------------------" >> /home/user/test/backup/backup.logecho "закончено"
renbuar.blogspot.com